redis内存总是有限的,即使服务器内存很大,假如180g,你也不会让一个redis实例使用180g的内存,因为redis在做持久化等等操作时时间成本很大,一般都是几个G就可以了,这样所有的环节都很轻盈,而且假如你让redis很大,因为一个redis进程要管理那么多的内存,序列化,持久化,就会相对慢一些,那么当数据量比较大的时候,我们要怎么往里面放呢?
一、大数据量在集群中的存储(作为缓存用)
1、客户端层面解决
常用的三种分区方式:
a、按照业务划分(数据可以分类,交集不多)
根据上一篇文章中说的,在Y轴拓展,多个redis实例,比如一个实例存a开头的key,另一个实例存b开头的key,或者按照业务划分,一个实例存商品,一个实例存购物车等等
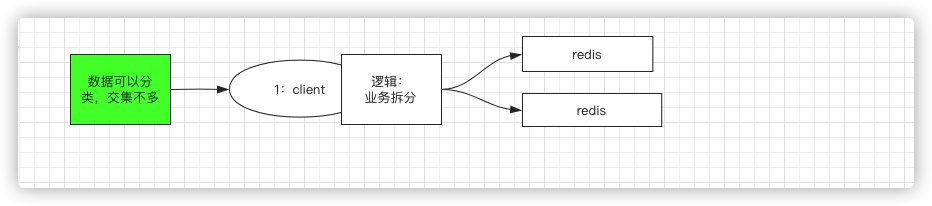
b、不能按照业务拆分时
当数据按照上面的方式无法拆分的时候
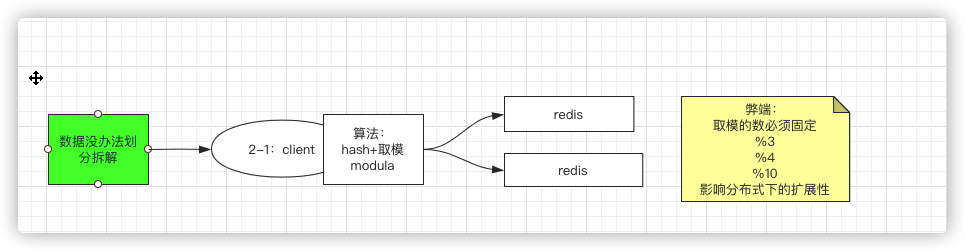
按照算法拆分(modula)
比如hash+取模,这个时候,其实就已经属于sharding分片了,所有的片数据何在一起就是所有的数据
弊端:
hash+取模天生的弊端就是取模的值必须是固定的(模是redis实例的台数),那么因为台数的变化(分布式下扩展机器),取模结果就会是不一样的,那么同样的数据可能就会去到不同的实例。
因此弊端就是: 影响分布式下的扩展性
random方式
客户端的数据随机各个实例中去扔,比如我要扔许多key都为k1的数据,这种方式更倾向于使用list存储,并且使用lpush,那么因为是随机,所以各个实例中就都可能有k1,但是会有个问题,那就是因为是随机的,所以你找不出来。因此需要增加一个客户端,链接其他的redis,然后这个客户端使用rpop获得数据消费就可以了
这种场景是消息队列用的最多的一个场景

而这里的k1,就是topic;每一个redis就是partition,说到这里,我们就回想到kafka也用的是这项技术,只不过kafka是基于磁盘的,数据可以重复消费。redis是基于内存的,速度非常快
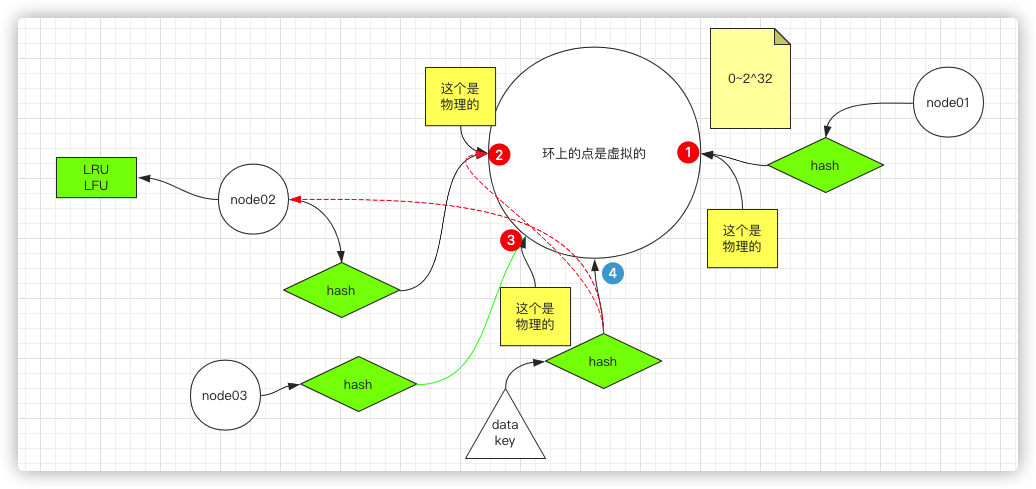
一致性hash算法-kemata
hash算法,属于映射算法(无论给出多短、多长、多复杂的字符串,经过算法后,都会给出一个等宽的值,和字符串做一个映射),首先这个过程是不会取模的,所以不会受限于物理机的个数,其次,根据算法算出等宽的hash值,那应该放在那一台节点上呢?所以算法会要求key和节点node都要参与算法计算的,一般会抽象成一个hash环(这里暂时不对算法做过多解释)
1、首先有一个环形,这环形很大,比如从0开始,到2的32次方,注意现在上面的点都是虚拟的点;
2、有几台redis节点,每台可以给它一个ID号,或者IP+端口号,或其他唯一的信息
3、首先node01节点经过算法,可以产生一个映射值,同理node02也会拿着2中说的唯一值进行算法计算,映射到环上的某一个点,这个时候这个点是物理的
4、当存数据的时候,key值也做hash计算,然后对应都某一个点。
5、准备一个算法,比如treemap等具备排序的,将所有的物理点放在类似于treemap上,拿着key得出的hash值对应的点,在treemap中去找,找到凡是大于这个点的物理点有哪些,离的最近的点对应的物理及,就是数据存储的节点,存储即可
6、如果相加一个node03,通过上面说的方式,计算之后的点正好对应到node01和node02之间
7、当需要查询一个key的时候,本来是存在node02的,但是因为加了一个节点,虽然不影响3~2区间的数据查找映射关系,但是4~3之间的数据就会从node01中去查。但这不是什么问题,因为我们的本意就是需要增加节点来分担部分数据量。只不过会有些缺点
缺点 :新增节点会造成一小部分数据不能命中
优点 :增加了节点,的确可以分担其他节点的压力,不会造成全局洗牌(hash+取模就会造成洗牌)
由于增加节点带来什么问题呢?
如果数据是在数据库存储的,那么就会造成缓存击穿
稍显笨拙的解决方案
每次取离最近的两个节点,但是这样会增加复杂度,这个取舍就在与你怎么考虑了
8、因为是用在缓存中的,所以数据是有可能缓存住的,有可能没缓存住的,没缓存住的,可以再加载一下,同时,可以对节点开启LRU、LFU淘汰机制
9、当然也会存在数据倾斜的问题,比如就两个节点,可能所有的数据都落在小于某一个环值的节点上,这个时候可以在步骤2的过程中,在唯一值后拼10个数据,每个节点都这样,比如node01,我分别拼1~10,那么经过计算就会找到10个点,node2同理,那么这样实际上就会有20个点是物理点。
因此可以通过虚拟节点间接解决数据倾斜的问题
因此这种方案一般都是倾向于在作为缓存使用,而不是数据库
2、代理层面解决(redis客户端链接成本高的问题)
实际情况不会像上面举例说的一个客户端,通常会有很多客户端,一个key的数据可能存在不同的实例中,所以就会有下面这张图
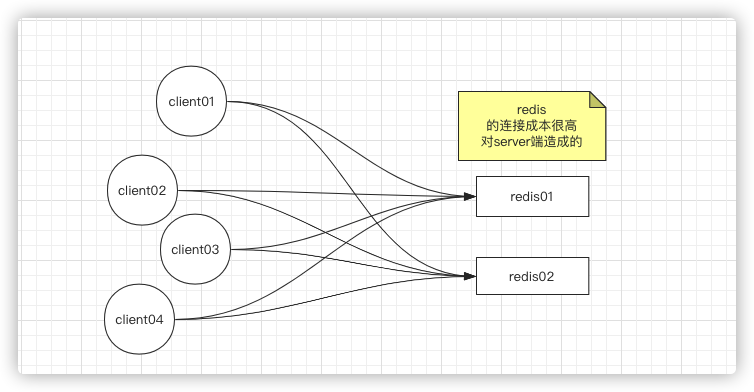
这样就会对server端造成很大的链接成本,那该如何解决呢?可以通过nginx做反向代理服务器(很多人不知道正向代理和反向代理的区别,看这篇文章),
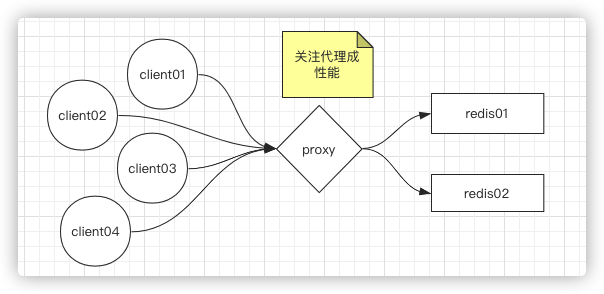
这种方式就可以解决,客户端链接过多对server的成本。那么只需要关注代理的性能就可以了,
那么当客户端非常多的时候,怎么才能hold压力----做一个nginx集群
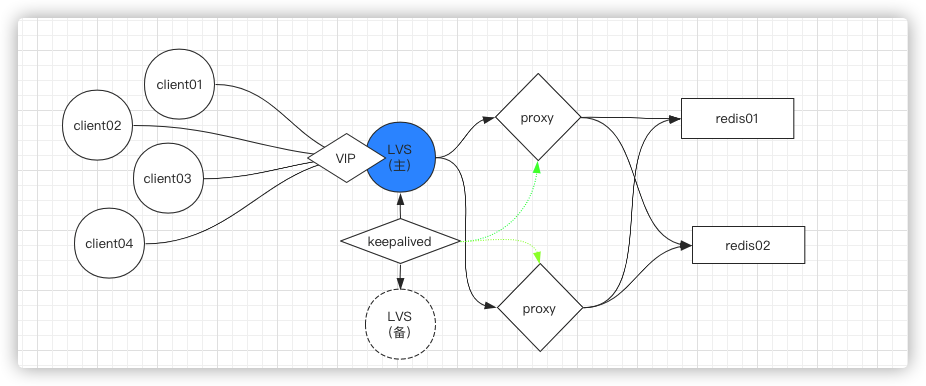
redis作者强调过redis连多线程都没有涉及,就是单线程,单实例,所以它其实更期望实际中就拿redis单个去使用,不要引入太多的技术
以上的两大块问题涉及到的知识点来源于twitter的一个开源项目twemproxy,可以在这里看到你熟悉的东西,有兴趣的可以看一看
因此讨论这么多,依然还是这三种模式,modula、random、kemata,只不是这三种模式是放在客户端实现还是在代理层实现的,如上面的的就是将模式放在代理层进行实现的
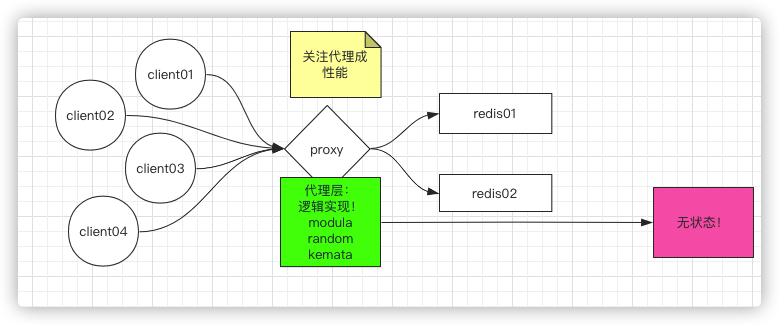
并且三种模式的缺点都是一致的,就是只能拿来做缓存,三个模式中最好的是一致性hash,但是一致性hash增删节点的时候会造成数据的时间窗的丢失、不可用,所以只能用来做缓存。
不能做分布式数据库使用
那如何解决这个问题呢?
二、【Redis集群方式三】Redis Cluster集群
上面说到三种模式都只能作为缓存使用,不能作为分布式数据库使用,那如何解决呢?–预分区
不论是在客户端层面实现三种模式还是在代理层实现三种模式,我们都可以使用预分区的思路来解决
1、拿hash+取模举例
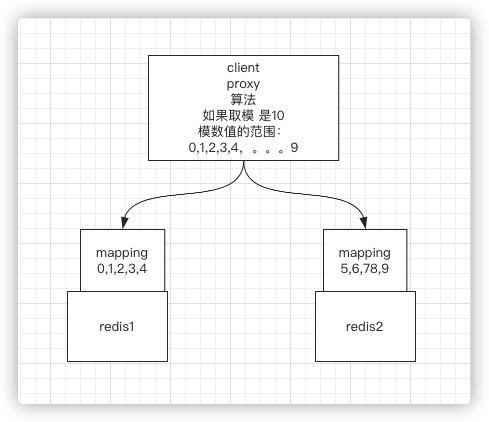
1、比如是hash+取模:之前两台时取模的时候是取2,那么为什么不直接使用10,也就是说未来可能增加到10个节点,如果是10,那么取值范围就是0~9,只需要在中间夹一层mapping关系。
2、当是两个节点的时候,比如节点1领取01234槽位,节点2领取56789槽位,因此每个节点各有5个槽位或者分片
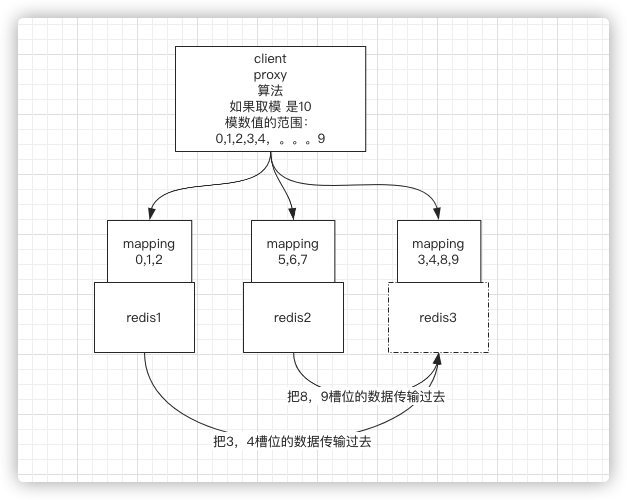
3、如果再加一个节点,在mapping中,让出一个节点,这样数据也不需要再rehash一遍,节点1让出3,4槽位的数据,节点2让出8.9槽位的数据,将这些数据迁移到新的节点即可
有了上面的知识,其实redis集群 自己要做的更好,不需要代理层:
1、比如有N个节点,并且是没有主节点的,每个节点会分数所有数据的1/N,客户端连服务端的时候,想连谁就连谁。
2、比如客户端现在要get k1,而k1真实存储在第三个节点上,并且在4号槽位(hash%10之后得出的槽位),而客户端直接链接到了节点2,相当于是将hash+取模操作放在了服务端,各个节点上去处理(之前是在客户端或者代理层处理),节点2收到请求之后,拿着k1做hash+取模算出槽位,和自己的mapping做比对,另外,每个节点上都会有所有节点的映射关系,也就是说,每个节点不但有算法,还有其他节点的映射关系
3、如果取模后,发现槽位4实在节点3 ,那这个时候就会返回给客户端,需要客户端重定向到节点3,节点3还是拿着k1做hash+取模运算,然后找到返回就可以了
Redis集群是自动分片和高可用的首选方案
上面👆就是redis的cluster模式,他是一种无主模型
那为什么要实现redis Cluster
1.主从复制不能实现高可用
2.随着公司发展,用户数量增多,并发越来越多,业务需要更高的QPS,而主从复制中单机的QPS可能无法满足业务需求
3.数据量的考虑,现有服务器内存不能满足业务数据的需要时,单纯向服务器添加内存不能达到要求,此时需要考虑分布式需求,把数据分布到不同服务器上
4.网络流量需求:业务的流量已经超过服务器的网卡的上限值,可以考虑使用分布式来进行分流
5.离线计算,需要中间环节缓冲等别的需求
可参考:https://www.cnblogs.com/williamjie/p/11132211.html
官方总结: 一定要看,非常重要,可以帮助很好的理解上面的推导~


但是数据一旦分治之后,出现在不同的节点上,那么数据聚合就很难实现,比如一个操作需要几个key,比如相对两个list取交集,再比如事务,因为他们被存到了不同的节点上,那如何实现?
2、hash_tag解决数据聚合问题
数据一旦分开,就很难整合起来,如果数据不被分开,那么前面担心的聚合操作就没问题了,
如果key是这样的,{oo}k1,{oo}k2,做计算时拿着前面的{oo}做哈希取模运算,那数据肯定就会落在一个节点上,这样数据就不会分开了
这就是hash_tag:将key进行hash_tag的包装,然后把tag用大括号括起来
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !