上一片文章中说到会拿redis做数据库,那么数据库就需要持久化,因为内存中的东西,掉电易失。
首先是单机持久化 ,再有单机也不靠谱的时候,主从复制
数据存储,都关心两类东西:1:快照/副本;2:日志
在redis中,也有这两种持久化机制:
RDB(Redis DataBase)描述的就是快照/副本。
AOF(Append Only File)描述的就是日志。
一、RDB(Redis DataBase)
时点性:比如8点整开始备份,但a=1是8:00落的,等到备份到b=2的时候,已经是8:05分了,而8:00的时候,b可能还是0。时点混乱
期望:
1、非阻塞,即在对外提供服务的同时,依然可以将数据落地,持久化
Linux中的一个小知识-管道
衔接,前一个命令的输出作为后一个命令的输入
管道会触发创建子进程
2
3
4
echo $$ | more # 使用管道会创建一个新的子进程,但是这里$$优于管道的,所以会被转化成当前进程
echo $BASHPID | more # 这里就会创建一个子进程
# $$ 高于 |
使用linux的时候:父子进程
父进程的数据,子进程可不可以看得到?
常规思想 :进程是数据隔离的!
进阶思想 :父进程其实可以让子进程看到数据!
export的环境变量,
子进程的修改不会破坏父进程
父进程的修改也不会破坏子进程
Tips:执行一个脚本的时候,想让他在后台执行。只需要在命令后面加上
&,比如:./test.sh &
创建子进程的速度快吗?或者如果父进程是redis,内存数据有10个G,如果要做到非阻塞的情况下,还有做数据持久化,那么根据上面的知识,我们知道,我们可以在准备持久化的时候创建一个子进程,来处理数据持久化。那么:
1、速度快吗?
2、内存空间不够吗?父进程10g,那么子进程也是10个G,空间还够吗
这个时候就有一种系统调用-fork()
1、系统调用fork()
它其实使用的就是指针的引用,它可以达到效果:
1、创建速度很快
2、空间要求也是小的(子进程占用很小的空间)
计算机中有物理内存,其实就是一个线性的地址空间,里面是很大的字节数组,redis会有一个虚拟地址,它里面的地址会映射到物理内存的某个地址
而通过系统调用fork()出来的子进程,也是一块虚拟内存,它并不是说把数据拷贝过去了,而是指针指向物理内存中的地址
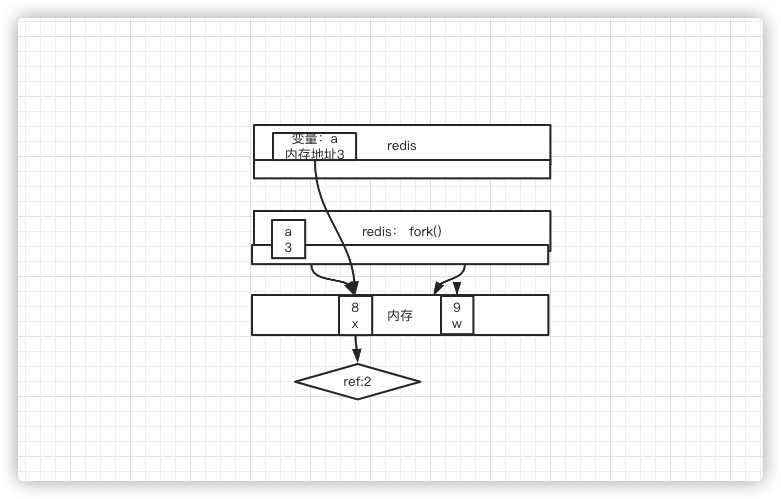
2、copy on write写时复制机制,(COW)
即创建子进程的时候并不发生复制(指针拷贝)
优势:
1、创建进程变快
2、根据经验,父、子进程不可能把所有数据都改一遍
a在redis虚拟内存中的地址是3,指向物理内存地址为8的地方,改之前物理内存a的值是x,现在要把a的值改成8,那么要怎么改呢,需要先出现w,然后再把w的值赋給某一个引用
如果有多个调用者(callers)同时要求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的(transparently)。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
因此这就会解决上面时点混乱的问题 了,8点创建的子进程,那么这个时候子进程就有了8点时所有的数据的指针,这之后,父进程的数据修改,不会影响子进程的数据(父子进程对数据的修改,对方看不到(数据是隔离的)),也就是父进程中a已经指向到了一个新的内存地址,但是子进程中的依然是8点时的内存地址
注意:
fork()是系统调用,COW是内核机制
3、具体实现
a、使用命令
save前台阻塞、bgsave后端异步的非阻塞命令,bgsave会触发fork,创建子进程。
但是人为的执行多少有些不靠谱,所以也支持在配置文件中编写一个bgsave规则
注意在配置文件中用的是
save这个标识,但是触发的是bgsave
那是不是save命令一点优势都没有了,也不是,会在哪里用到呢,只要是服务不关机,不做任何停服的时候,肯定使用bgsave,但是如果是关机维护的时候,就必须做一个save,存一个全量数据,否则就丢失数据了,虽然这种场景不是特别常见
redis中关于这块的配置
1 | ################################ SNAPSHOTTING ################################ |
上面的配置,也可以关闭不用,save ""即可,即打开18行的注释。注释22~24行
redis默认是开启了RDB(快照/副本)功能的
其他配置:
rdbcompression yes:是否开启压缩
rdbchecksum yes:新版本增加的,会在文件的最后写一个交易位
dbfilename dump.rdb:给落下来的文件起个名字dump.rdb
dir /var/lib/redis/6379:落下来的文件存放路径
4、弊端
1、不支持拉链,只有一个dump.rdb,需要运维定制定时策略,备份每个备份按照日期存储
2、丢失数据相对多,因为他不是实时记录数据的变化,时点和时点之间窗口的数据容易丢失,比如8点备份了,9点的备份还没做,挂机了,那么就丢失了一个小时的数据,和hdfs、fsimage弊端是一样的
5、优点
类似Java中的序列化,其实就是把内存中的字节数组,以最快的速度搬到磁盘中去,所以恢复的时候也直接恢复,即恢复的速度相对快
基于4中所说的弊端,就有了AOF
二、AOF(Append Only File)
AOF,即只会向文件追加,所谓的追加即服务器的写操作。
1、每一个写的操作,都会追加到文件,这样做的好处就是丢失的数据少
2、RDB、AOP可以同时开启,但是注意,如果同时开启,重启服务器的时候,恢复的时候只会拿AOF恢复
新版本4.0之后,AOF中包含RDB全量,增加记录新的写操作
问题:Redis运行了10年,开启了AOF,在10年的时候挂了:
a:AOF多大?
AOF可以有10个T嘛?可以,因为是一直append,写、删操作,记录的操作记录(操作指令)
b:恢复需要多久?会存在内存溢出的情况嘛?
不会发生溢出操作,这10个T很多前面创建,后面删除,后面拿删除的空间再去创建,,所以只要线性的执行这个文件,最终就会恢复,不会溢出
要溢出,在写入内存的时候就会发生溢出,不会写到文件中去的。
恢复多久?恢复5年可不可以?当然是有可能的,因为存的是指令,需要一条一条的执行
因此,会存在的弊端:
1、体量无限变大
2、恢复慢,
那如果在不丢失数据的情况下,AOF足够小
在
hdfs、fsimage中,用hdfs、fsimage+edits.log,把日志中的东西记到一个镜像当中,日志就会被清空,到下一个时点,日志就只会记增量
Redis中是如何实现的
1、4.0以前,重写,抵消和整合命令,删除抵消的命令,合并重复命令
比如:一个key,前面一系列的创建,删除,最后一个还是创建,那么其实前面的都不需要管了
或者有一个list,10年一直在push 1,那么可以计数后,直接一次push总和个1
但是恢复成本还是挺高
2、4.0以后,重写时,先将老的数据RDB,写到AOF文件中,再将增量的以指令的方式Append到AOF中
AOF是一个混合体,利用了RDB恢复快,利用了日志的全量
1、AOF的三个级别
Redis是一个内存数据库,但是现在增删改的时候,就回触发I/O操作,因为要向磁盘中去写,所以会拖慢Redis内存速度,因此AOF有三个界别配置可以调
NO、always、everysec:
一个常识:
在Java编程的时候嘛,如果要打开一个文件往里面写东西,写完之后,必须要写一个
flush,因为,在计算机中,所有对磁盘硬件的I/O操作就需要调用内核的,比如内核中的文件描述符是8,那么在调用内核的时候,内核会开一个buffer,Java程序写的时候,先是写到buffer中,buffer满了之后,内核就会向磁盘去刷写,或者通过flush刷写。那么Redis同理
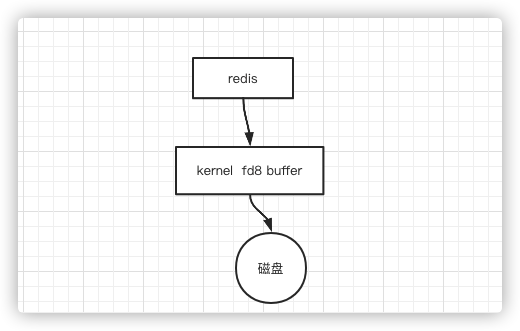
Redis配置文件中,有一些配置
1 | appendonly no # 默认是关闭AOF的 |
三个级别:
no: redis收到N个写操作,每笔都会写到内核的buffer中,no的意思就是redis不调用flush,而是buffer什么时候满了,什么时候去刷写,这样存在的问题就是可能丢失一个buffer大小的数据
always redis发生一次写操作,就调用一次内核,再调用一次flush,把数据刷进磁盘。数据最可靠的
everysec:redis每一秒中调用一次flush,相对丢的数据较少
三、实战
1、修改配置
a、老版本的配置
修改daemonize为no,即我们不让他作为后台进程服务运行,,在前台阻塞着运行,
注释文件地址,让日志直接打印到控制台,不然就会写到日志文件# logfile /var/log/redis_6379.log
修改appendonly为yes,开启AOF,
暂时先关闭混合,修改aof-use-rdb-preamble为no
如果/var/lib/redis/6379下已经有生成的dump.rdb文件,先删除(⚠️注意,这里是为了学习测试使用,别把真实的有用的数据删除了)
先确定redis是没有启动的,然后启动服务
1 | [root@hadoop01 6379]# redis-server /etc/redis/6379.conf |
查看刚才目录下生成了一个文件
1 | [root@hadoop01 6379]# pwd |
再开启一个客户端:
1 | [root@hadoop01 6379]# redis-cli |
再次看持久化目录/var/lib/redis/6379,没有dump.rdb,因为没有触发那三个条件,查看 appendonly.aof文件,这是文件中的内容
1 | *2 # * 代表有几个元素,分别是下面的select和0 |
继续添加,文件也会继续追加。
因为目前还没有满足save的触发条件,所以我们可以使用save或者bsave写rdb文件
1 | [root@hadoop01 6379]# redis-cli |
同时我们看到服务端:
1 | ... |
响应的目录下也多了一个dump.rdb,可以查看这个文件,但是存的是序列化的,所以可以使用redis-check-rdb dump.rdb看一些信息:
1 | [root@hadoop01 6379]# redis-check-rdb dump.rdb |
我现在继续在客户端对k1设置值
1 | 127.0.0.1:6379> set k1 1 |
这个时候, appendonly.aof文件就会将这些命令追加了,文件大小此时为158个字节
1 | [root@hadoop01 6379]# ll |
那其实这个文件中许多就是没用的,所以我们做一个重写BGREWRITEAOF
1 | 127.0.0.1:6379> BGREWRITEAOF |
再次查看文件大小,发现已经减少到了52个字节
1 | [root@hadoop01 6379]# ll |
再去看appendonly.aof文件,发现中间的一些命令在文件中已经没有了,抵消掉了
b、新版本的配置
Ctrl+C结束服务端,关闭客户端,把刚才生成的两个文件都删除掉
修改配置aof-use-rdb-preamble为yes,目录下就会多一个appendonly.aof文件,目前还是空的,开一个客户端
1 | [root@hadoop01 6379]# redis-cli -p 6379 --raw |
此时的appendonly.aof文件,依然是存的上面的每条指令,这个时候再执行:
1 | 127.0.0.1:6379> BGREWRITEAOF |
这个时候再看appendonly.aof文件的时候,发现存的是RDB的内容了
1 | REDIS0009ú redis-ver^E6.0.0ú |
继续set
1 | 127.0.0.1:6379> set k1 1 |
这个时候appendonly.aof文件中,这两条命了就会以AOF的方式追加到文件中(时点数据+增量日志)
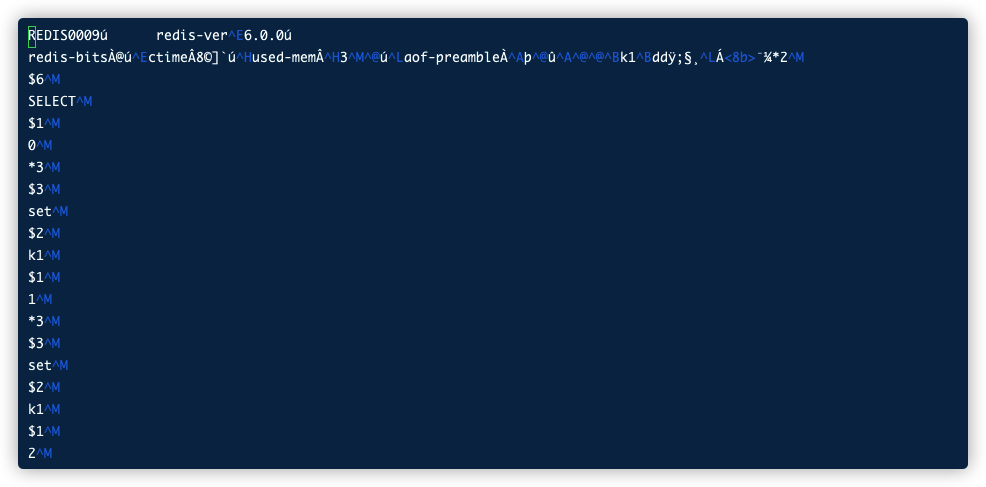
等到下次再BGREWRITEAOF,就会再次触发重写,把刚才一些命令做抵消,以RDB的方式重新存在appendonly.aof中
因此需要注意了,加入你再这个时候,不小心输入了
flushall,内存中的数据都没有了,那这个一定要注意不要执行BGREWRITEAOF,因为appendonly.aof文件的最后就是flushall,可以认为的删除flushall及前面的*、$,这样恢复数据的时候就不会丢失
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !