一、引言
刚有计算机的时候,数据可以存在文件里,那如果我们要查询数据的话,Linux中有grep、awk等这样的命令,用Java语言的话,写一个程序,基于这个文件的IO流读写操作,那还有什么其他问题嘛?
一些常识
在计算机中,数据是存在磁盘中的,磁盘有两个指标:
1、寻址:寻址的速度是毫秒级的
2、带宽:即单位时间内可以有多少个字节流过,多大的数据量流过去,一般是G或者M级别的
另外,还有一点就是内存,内存也有一个寻址,它的寻址速度是纳秒 (秒->毫秒->微妙->纳秒[换算是1000])
磁盘比内存慢了100万倍,是在寻址上慢了100万倍(因为内存是直接怼在了CPU的前端总线),所以带宽会占用很大
IOBuffer:
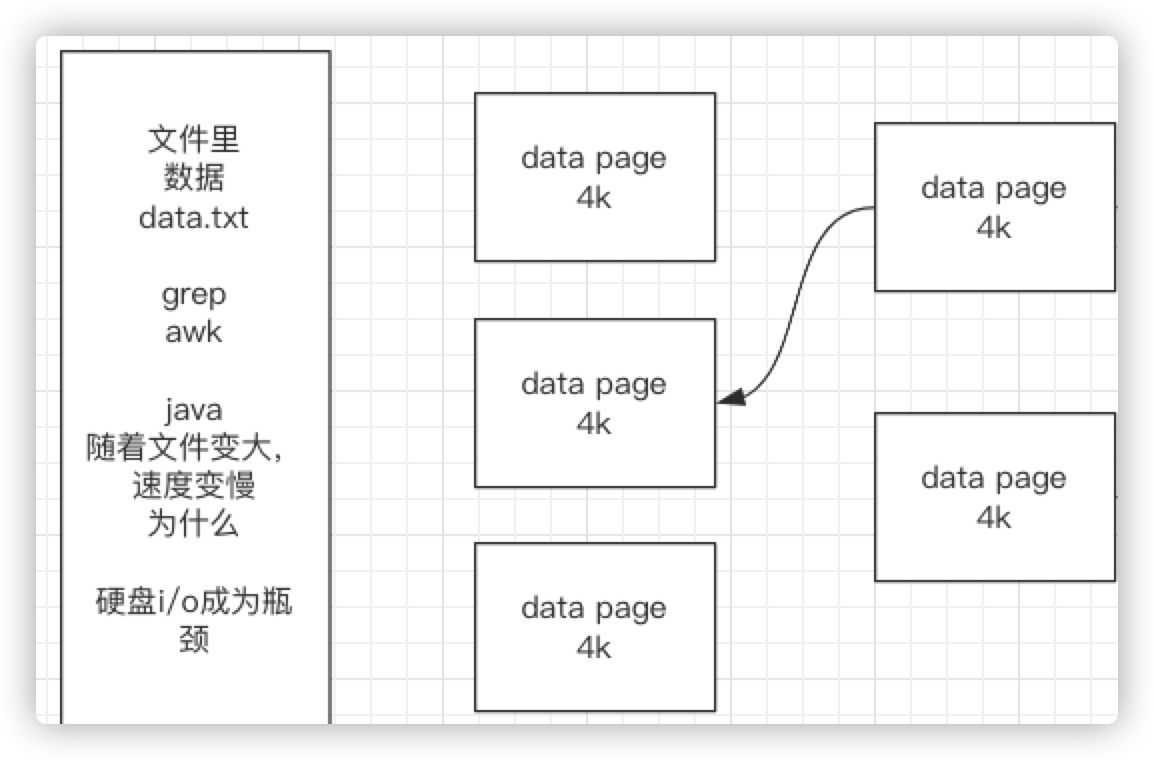
这是一个成本问题,磁盘有磁道和扇区,一个扇区512字节,如果访问一个硬盘,都是最小粒度512个字节来找,而一块硬盘一般是1T、2T,会有非常多的512字节,如果区域足够小,那么索引成本就会变大,也就是说如果有1T空间里面都是512字节的小格子,那么上层操作系统中就需要准备一个索引,这个索引可能就不是4个字节了,可能得8个字节或者更大,他要一个能表示很大数的区间,才能索引出这么多的小格子,所以索引成本会变大。
所以在格式化磁盘的时候,有个4k对齐,也就是真正使用磁盘的时候,并不是按照512字节为一次读写量,它会把这个变得大一点,即不管你读512字节也好,读1k也好,硬盘都是直接给你返回4k。512字节和4k就差了非常多,所以索索引体量就会随之变小。因此一般磁盘模式格式化4k操作系统,即无论读多少都是最少4k从磁盘拿的。因此,如果数据是存放在文件中的,随着数据慢慢变大,查询速度就会变慢。也就是硬盘成为瓶颈了,即I/O成为瓶颈。
这个时候,数据库就出现了,数据库有一个data page的概念,data page 的大小也是4k,现在有一张表,物理存储到磁盘的时候,用了许多的4k这个的小格子,而这个4k小格子,刚好跟硬件上的磁盘的最小读写量4k一致,也就是说,如果要读取4k里面的数据,正好符合磁盘的一次I/O,就没有浪费这个I/O
因为假如data page是1k,那到底层还是4k,这就是上面说的浪费,数据库读1k,底层还是读4k,索性直接读4k.
如果只是4k的小格子,其实查找数据的成本复杂度还是跟前面差不多,因为还是要从第一个4k开始,先读到内存中,挨个去找,所以还是走的是全量I/O,如何变快呢?
这就是索引,索引依然是使用的的4k这种存储模型对应的模型,无非就是4k的格子存的是一行一行的数据,而4k索引中存的是前面格子中的某一列,比如身份证那一列。索引中每一个身份证号指向某一个data page,这个指向关系就是索引
知识点:建立关系型数据库表的时候,一般使用什么存储方式?
通常我们建关系型数据库表的时候,必须给出
schema,即这个表的列数,每个列的类型是什么,约束是什么。每个列的类型其实就是字节宽度,当插入数据的时候,即使是空的字段,也会用0或者空的取填充,这样做的好处是什么呢?
表中有个概念,就是存储的时候更倾向于行级存储 ,这样,不管插入什么时候,不管有没有空,字段都会去占位,占位又个好处,后面的增删改,,不用移动数据,直接拿数据往这个位置复写就好了
另外,数据和索引都是存储在硬盘当中的,查询的时候,会用到B+Tree,B+树的所有的叶子就是这些4k格子,B+Tree树干是在内存中的,查询的时候,where条件中命中某个索引,这个查询就会走树干,找到某个叶子,也就能找到对应的data page。但是如果把这些索引都存在内存中,数据量很大的时候,索引也会随之变大,内存不一定够用,所以索引也是存在磁盘中,只把树干存在内存中,只存一些区间;
所以,充分利用各自的能力,磁盘可以存很多东西,内存速度快,然后用一种数据结构可以加快遍历查找的速度,这样最终的目的就是减少I/O的流量,即不让他发生大量的I/O以及减少寻址的这个过程。
那么当表中的数据很大的时候,性能会下降嘛?
首先对于增删改来说,如果表是有索引的,那么增删改需要修改索引或调整它的位置,即因为维度索引,导致增删改变慢。
那么查询速度会变慢嘛?
「1」、 1个或者少量的查询速度依然很快;
「2」、 并发大的时候会受硬盘的带宽影响
硬盘的慢,不止寻址慢,带宽也会是影响慢的一个重要因素
数据在磁盘和内存中存储的体积是不一样的。
解决上面这些问题的折中方案,就是缓存
二、Redis
官方描述
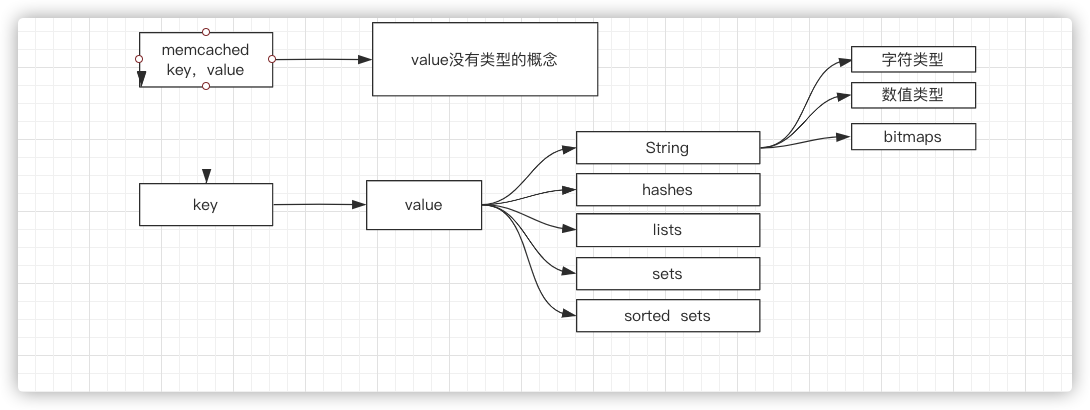
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。
它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。
Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。
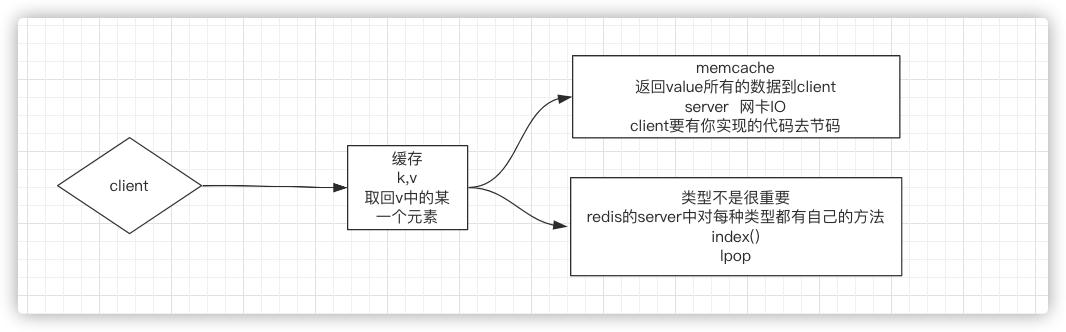
如果客户端想通过缓存系统,取回value中的某一个元素,成本是不一样的,memchche需要返回所有的数据到client,server网卡IO就会是瓶颈,另外,client需要有实现的代码去解析。而redis,因为他有类型,其实类型不是很重要,重要的是redis server 中对每种类型都有自己的方法。用大数据中的词描述就是计算是向数据移动 的;
计算是向数据移动:memcache获取需要的数据是需要返回后在客户端计算,而redis是在server中进行计算,只返回需要的少量数据
三、安装Redis
对于Linux
1 | //如果没有wget,需要使用`yum install wget`安装一个 |
即可下载安装包到当前文件夹,解压
1 | tar xf redis-6.0.6.tar.gz |
解压完之后,进入到redis的源码目录
源码安装的,记得第一步需要看一下README.me,基本上就会告诉你怎么编译、清除、安装等等
1 | Building Redis # 编译Redis |
所以,阅读README.me非常重要。
make的原理:make其实跟源码没有关系,make是Linux操作系统带的编译命令,他是不知道你下载的不同的源码包应该怎么编译,他必须找到一个文件叫Makefile;这里需要注意,我们之前安装nginx的时候,是没有
Makefile的,所以要先执行config之后就会生成Makefile文件,这个在nginx的readme中都有说明的所以
make命令直接执行的时候,其实是读取Makefile,它里面就是编译脚本
1 | # `Makefile`文件 |
如果什么都不输入的话,执行make命令,其实是cd src目录下,并执行make命令,当然,如果执行的是make install 其实就会走上面的第10行脚本
所以其实真的执行是在src下,这里面会有一个Makefile
我们到源码的根目录下,执行make,发现报错了
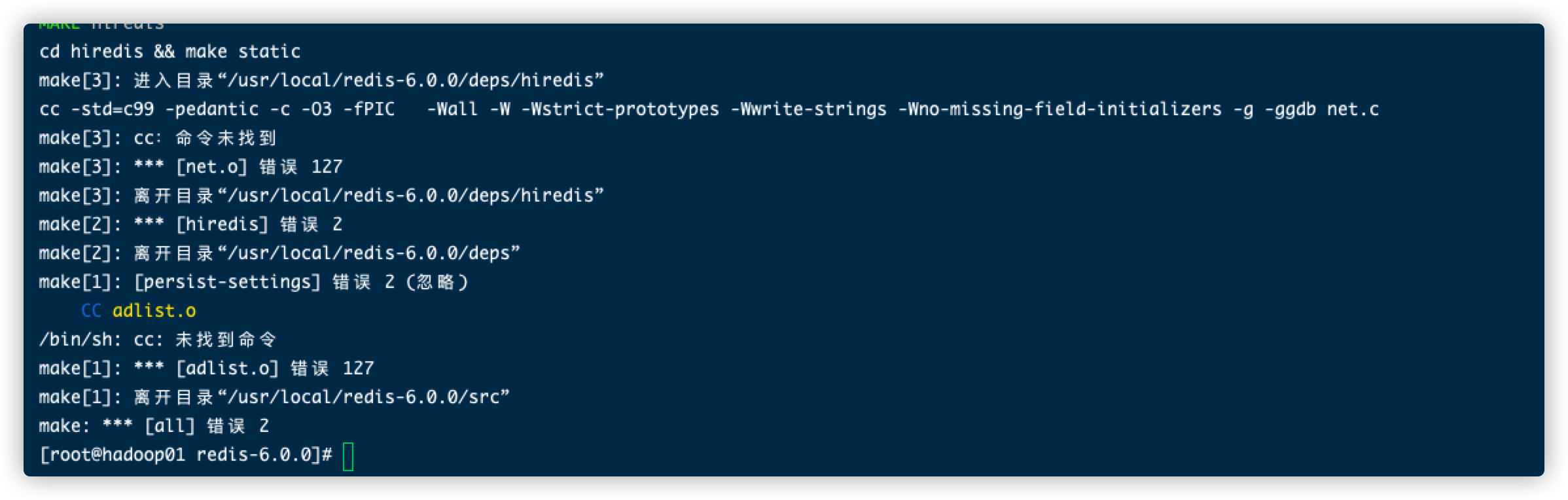
发现系统中没有c语言的编译器,那就安装一下
1 | yum install gcc |
安装完成之后,我们先执行一下cleanmake distclean,要清理一下刚才报错的那些临时文件,清理完之后,再次执行make,等到编译完成.执行make test测试一下.
这里需要注意,一些人在编译的时候,会报错,报很多类似于这样的错误
这是因为安装6版本的redis,gcc版本一定要5.3以上,centos6.6默认安装4.4.7;centos7.5.1804默认安装4.8.5,这里要升级gcc了。
解决:gcc -v可以查看gcc的版本,检查版本是否过低。升级命令
然后重新
make distclean,再次编译。
这个时候,在src下面就会有一堆的可执行文件,其中包括redis server和redis cli,这个时候,其实直接执行./redis-server就可以把服务跑起来了,但是这种启动方式比较low。我们肯定是期望是把redis的一个进程制更像一个软件。
根据readme文件中的指示进行安装
1 | make install PREFIX=/opt/redis # PREFIX指定自定义安装目录 |
这里我安装到默认的安装目录,即不指定PREFIX.
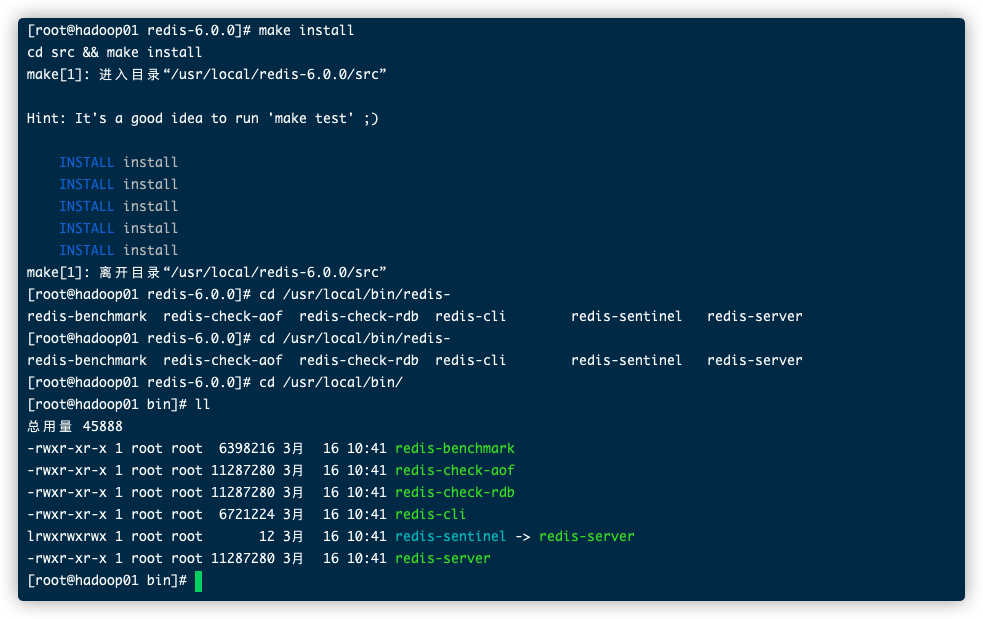
就可以在/usr/local/bin下看到可执行程序。
最后一步,把它变成服务。
在utils目录下,有个install_server.sh,但是这个脚本需要知道程序安装在哪个文件了,所以需要创建环境变量
编辑vi /etc/profile,在文件的最后面加上:
1 | export REDIS_HOME=/usr/local/bin |
保存之后,source /etc/profile。这样的话,就可以在任何地方直接可以使用redis-cli来启用客户端了.
然后在utils当前目录下执行./install_server.sh
如果出现
2
Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!解决方案:
vi ./install_server.sh注视这段代码:
2
3
4
5
6
7
8
9
_pid_1_exe="$(readlink -f /proc/1/exe)"
if [ "${_pid_1_exe##*/}" = systemd ]
then
echo "This systems seems to use systemd."
echo "Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!"
exit 1
fi然后重新运行
./install_server.sh即可。
这过程中,会让你选择端口好,所以说其实如果指定不同的端口,可以起多个;另外还有日志目录,数据目录
1 | [root@hadoop01 utils]# vi install_server.sh |
这样就安装完成了,此时,应该在/etc/init.d目录下有个脚本
1 | [root@hadoop01 utils]# cd /etc/init.d/ |
即redis_6379.
这个时候我们就可以在任何目录中,使用
1 | service redis_6379 start |
多实例安装
当然,我们也可以安装多个实例,还是到utils目录下。执行./install_server.sh,指定一个不同的端口好,比如6380
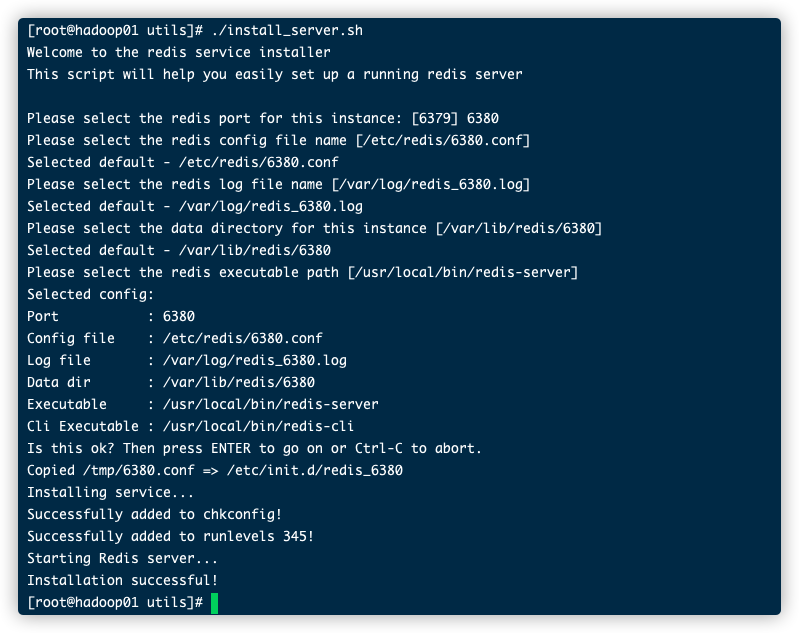
执行ps -fe | grep redis,不同的端口好,不同的进程

对于Mac OS
直接执行
1 | brew install redis |
四、NIO原理介绍
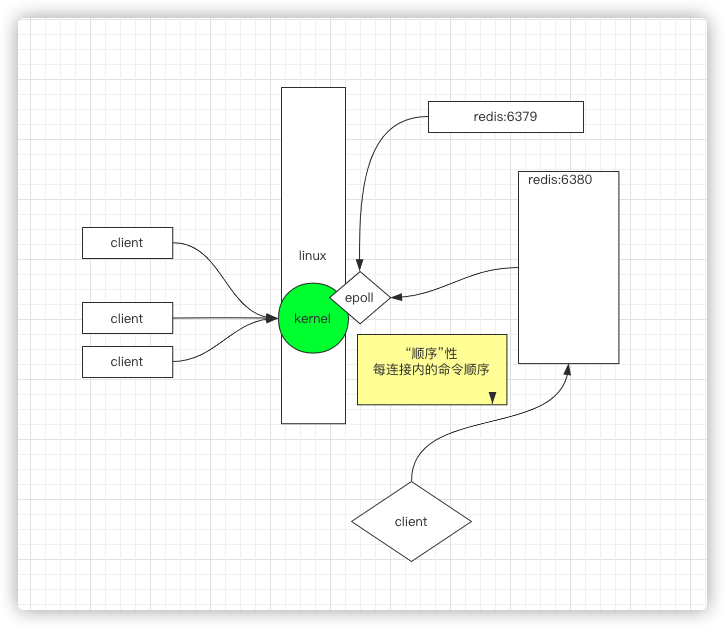
每个计算机中可以有多个redis进程。另外。redis 是单进程,单线程,单实例,那么当并发很多的时候是如何变得很快的。
操作系统是由一个内核(kernel)的概念的,所有的客户端的连接先到达内核,tcp握手,有很多的socket.
redis进程和kernel之间使用的是
epoll,即非阻塞的多路复用
什么是epoll?
内核(kernel)利用文件描述符FD(file descriptor)来访问文件。文件描述符是非负整数。打开现存文件或新建文件时,内核会返回一个文件描述符。读写文件也需要使用文件描述符来指定待读写的文件
Java中使用Object代表一个对象,代表一个输入输出流(inputstream、outputstream),linux不是面向对象的,一切皆文件,所以都是拿着文件或文件描述符来表示
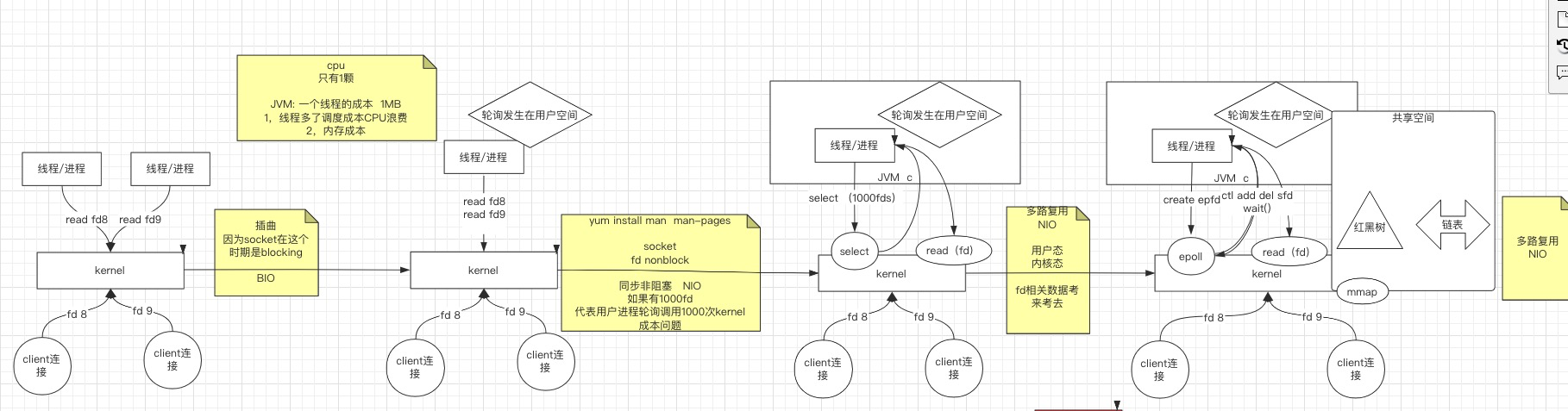
1、BIO时期
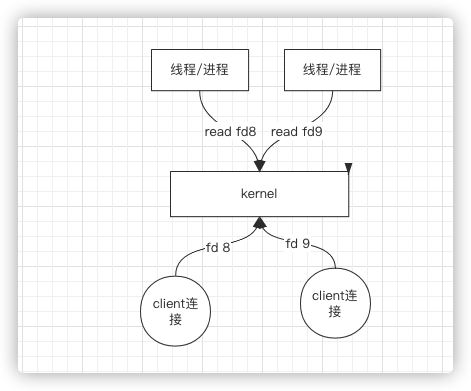
因为socket在这个时期是阻塞的(blocking),即socket产生的文件描述符,你读它的时候,在数据包还没到的时候,read命令就不能返回,就在这阻塞着
这就是**BIO**.抛出一个线程来读取网卡的连接,有数据就处理,没数据就阻塞着,如果只有一颗CPU的话,某一时间片上只有一个线程可以处理。
查看一个进程有多少个文件描述符,或者说有多少个I/O?(linux系统中一切皆文件)
2
3
4
5
6
7
8
9
10
11
[root@hadoop01 fd]# ll
总用量 0
lrwx------ 1 root root 64 3月 16 14:39 0 -> /dev/null # 0:标准输入
lrwx------ 1 root root 64 3月 16 14:39 1 -> /dev/null # 1:标准输出
lrwx------ 1 root root 64 3月 16 14:39 2 -> /dev/null # 2:报错输出
lr-x------ 1 root root 64 3月 16 14:39 3 -> pipe:[119354]
l-wx------ 1 root root 64 3月 16 14:39 4 -> pipe:[119354]
lrwx------ 1 root root 64 3月 16 14:39 5 -> anon_inode:[eventpoll]
lrwx------ 1 root root 64 3月 16 14:39 6 -> socket:[119358]
[root@hadoop01 fd]#0、1、2是每个进程中都会有的
为什么说这种一个线程对应一个连接会有问题?(100个client连接就有1000个线程)
在JVM中,一个线程的成本(Java内存中,堆是共享的,线程栈是独立的),栈的大小默认可以是1M,也可以调。
1、线程多了,调度成本CPU浪费
2、内存成本,按照上面的,1000个线程光线程栈就是近1g
2、NIO时期
这个时候内核发生了变化
内核当中,socket可以是非阻塞的(nonblock),不阻塞了就可以使用一个线程 ,采用轮训(while死循环),因此称为同步非阻塞(NIO)
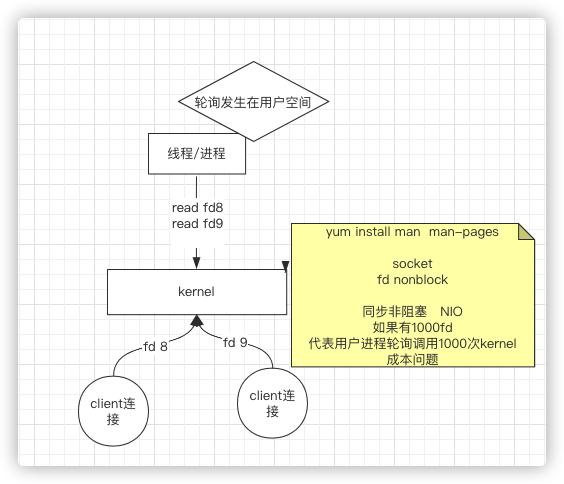
成本问题:如果有1000fd,代表用户进程轮询调用1000次kernel,如何解决?
根据描述,那就是减少调用内核次数,这个用户是无法实现的,所以还是要从内核出发
3、多路复用的NIO(依然是同步非阻塞)
就是将用户空间轮训的操作移到内核中,内核里从而多了一个系统调用select,内核监控更多的文件描述符。即以前调用1000次,现在调用1次,发现了50个,再拿这50个挨个挨个去read.–多路复用的NIO
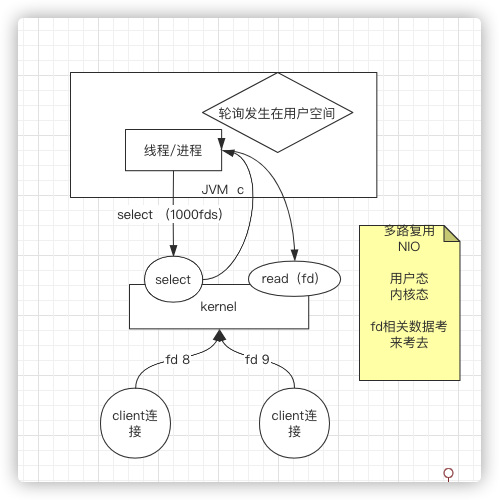
但是文件描述符fd传来传去,成为累赘了
4、共享空间(mmap)
共享空间(mmap)(内核实现的),即用户态、内核台有一个空间是共享的,
将之前的1000个文件描述符存储在共享空间
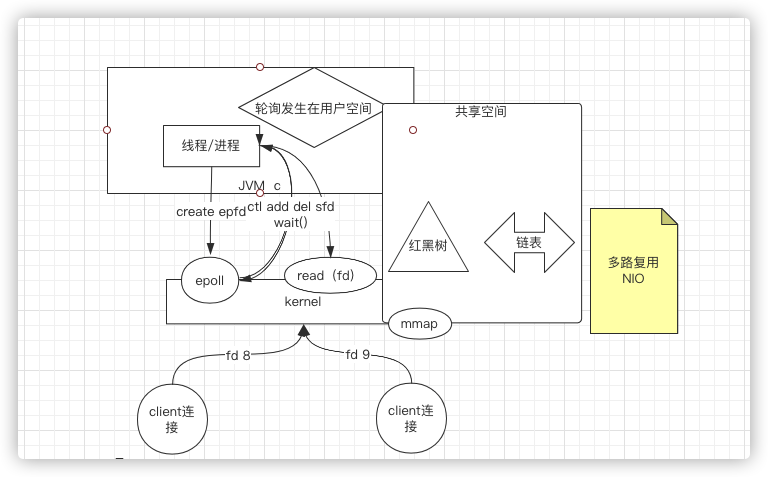
这点是为了解决文件描述符来回拷贝的问题,我们一般都会想到如果做到零拷贝,但是这里跟零拷贝是没有关系的,零拷贝是另外一个系统调用
内核中多了一个系统调用
sendfile文件的数据先到内核的buffer缓冲区,再read到用户空间,然后再write回来,最后再发出去,这里是由拷贝过程的,但是有了
sendfile之后,是直接调用了sendfile,内核读file放到缓冲区,再发出去,就不考来考去了
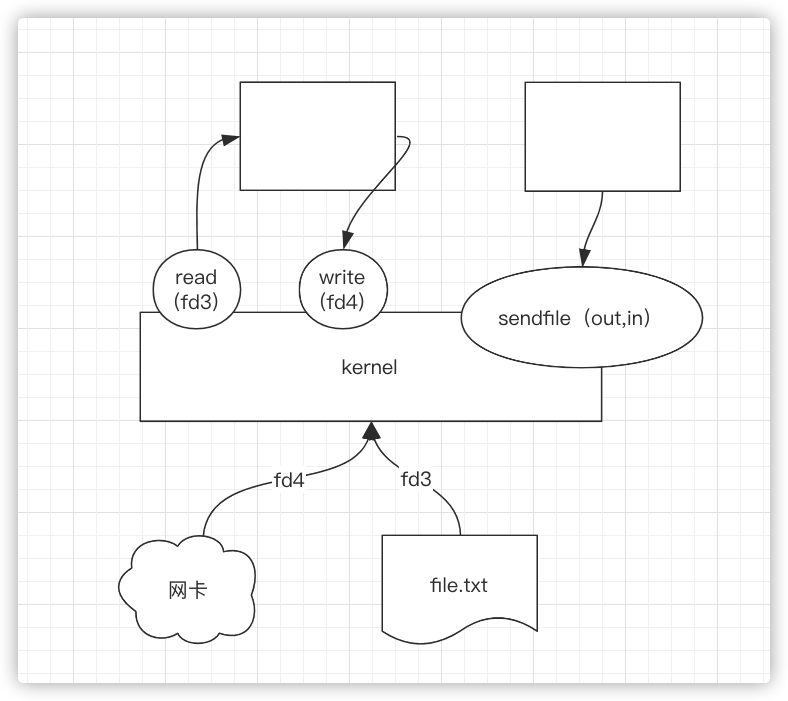
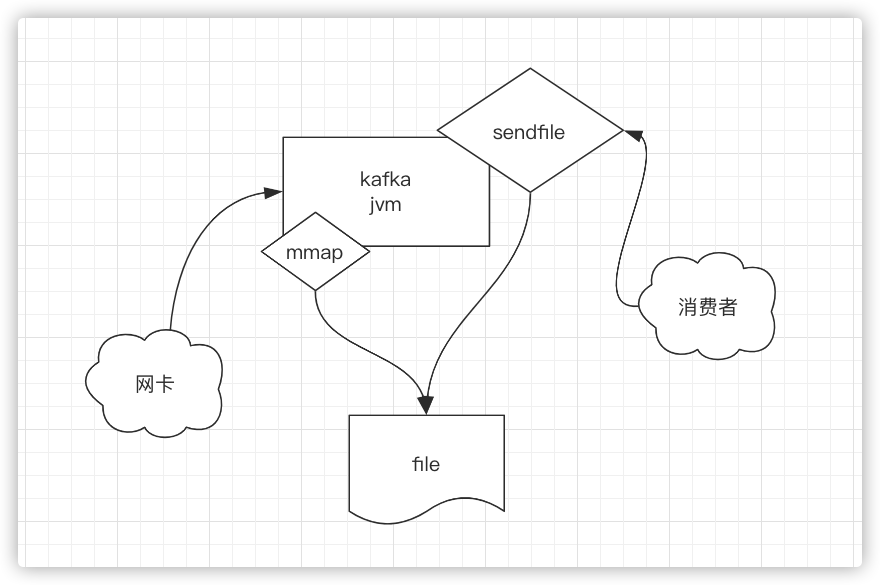
拓展:sendfile加上mmap就组建了一项高效的技术kafka
以上就epoll最终出现的历程
有了以上epoll的知识,再回到这张图上来
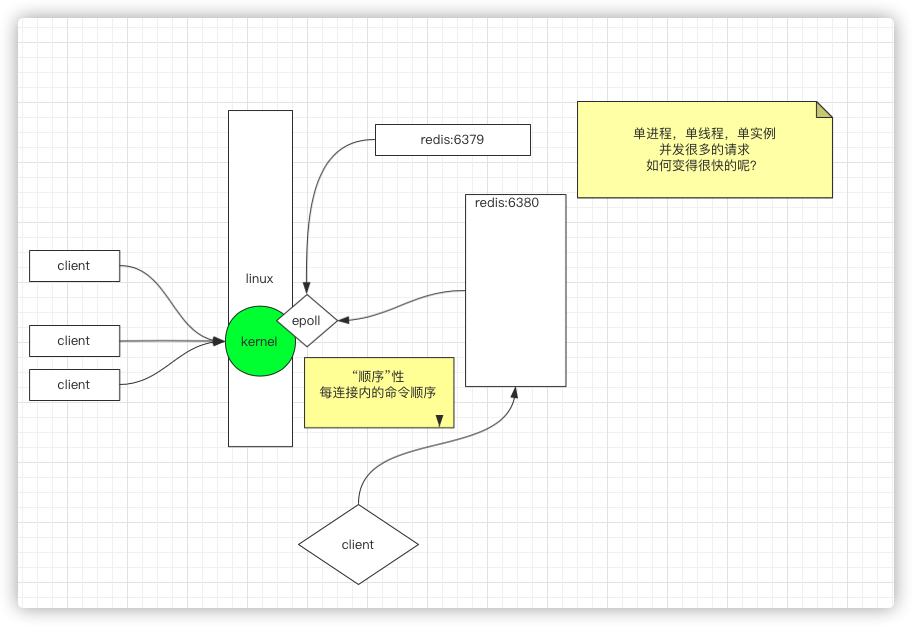
有很多client都连接了redis,站在redis的角度来说,就是进来的socket很多。redis-server是一个进程,进程就会调用epoll来遍历寻找那一个socket进来了,redis是单进程,单线程来处理用户的数据
但是redis就是一个线程么?不是,它还有其他线程再处理其他事,只是处理用户的数据操作是redis中的一个线程完成的。
这样会有一个好处,就是顺序性;这个顺序性是指每个连接内的命令顺序。即每个连接里面是顺序到达,顺序处理的
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !