Mysql 索引
磁盘预读(预读的长度一般为页(page)的整数倍)
页是存储器的逻辑块,操作系统往往讲主存和磁盘存储分割为连续的大小相等的块,每个存储块称为一页
在许多操作系统中,页大小通常为4k
主存和磁盘以页为单位进行数据交换
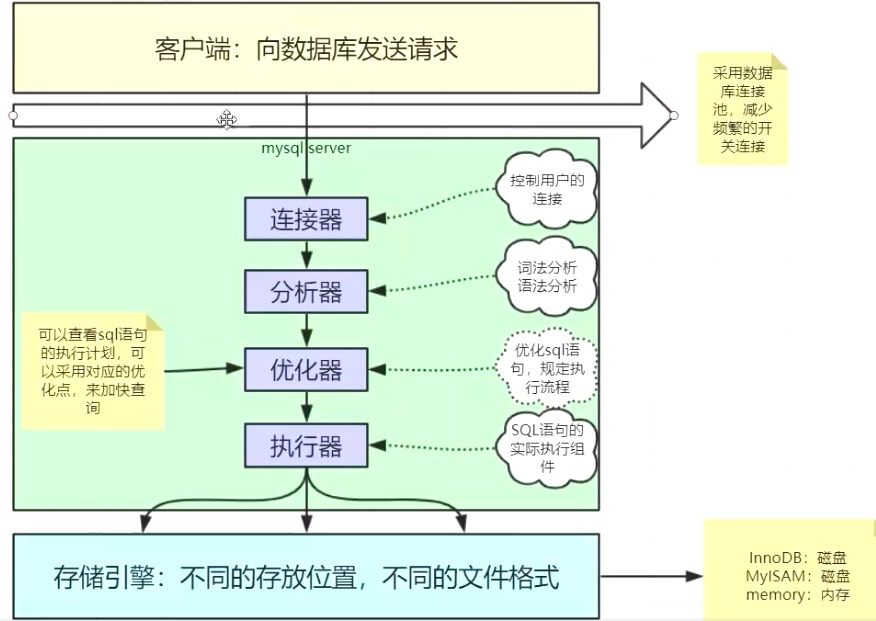
不同的存储引擎,数据文件和索引文件存放的位置是不同的,因此有了分类
-
聚簇索引:
数据和索引文件存放在一起;-Innodb
.frm:存放的是表结构
.ibd:存放的是数据文件和索引文件mysql的innodb存储引擎默认情况下会把所有的数据文件存到表空间中,不会为每一个单独的表保存一份数据文件。如果需要讲每个表单独使用文件保存,设置如下属性:
set globle innodb_file_per_table=on; -
非聚簇索引:数据和索引 文件单独存放 -myISAM
数据和索引单独一个文件
.frm:存放的是表结构
.MYI:存放的是索引文件.MYD存放数据文件
索引文件的结构
hash表
又叫散列表,哈希表可以完成索引的存储,每次在添加索引的时候需要计算制定列的hash值,取模运算后计算出下表,讲元素插入下标位置即可
适合场景:等值查询
但是表中的数据是无序数据(范围查找的时候比较浪费时间,需要挨个进行遍历操作)
hash表在使用的时候,需要把所有的数据都加载到内存,比较耗费内存的空间

树
在树的结构,左子树必须小于根节点,右子树必须大于根节点
多叉树:
从左到右是有序的
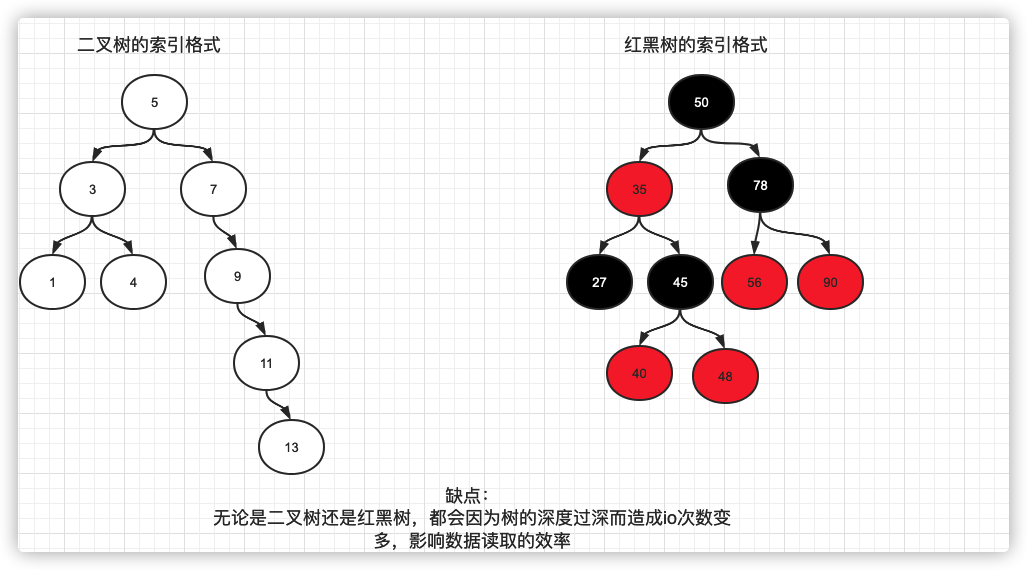
二叉树:
二分查找
AVL树:
平衡树 最高子树与最低子树的差不能超过1,所以在元素插入的时候,会进行1到N次的旋转,严重影响插入的性能
红黑树:
是基于AVL树的升级,损失部分查询的性能,来提升插入的性能,在红黑树中,最低子树根最高子树之差小于2倍即可,比如最低是4,最高层不能超过8层
意味着不需要进行N多次的旋转,并且还加入了变色的特性。来满足插入和查询性能的平衡
上面的树深度无法控制,或者插入性能比较低
B树:
B树特点:
1、所有键值分布在整颗树中
2、搜索有可能在非叶子结点结束,在关键字全集内做一次查找,性能逼近二分查找
3、每个节点最多拥有m个子树
4、根节点至少有2个子树
5、分支节点至少拥有m/2颗子树(除根节点和叶子节点外都是分支节点)
6、所有叶子节点都在同一层、每个节点最多可以有m-1个key,并且以升序排列

实例图说明:
每个节点占用一个磁盘块,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为 16 和 34,P1 指针指向的子树的数据范围为小于 16,P2 指针指向的子树的数据范围为 16~34,P3 指针指向的子树的数据范围为大于 34。
查找关键字过程:
1、根据根节点找到磁盘块 1,读入内存。【磁盘 I/O 操作第 1 次】
2、比较关键字 28 在区间(16,34),找到磁盘块 1 的指针 P2。
3、根据 P2 指针找到磁盘块 3,读入内存。【磁盘 I/O 操作第 2 次】
4、比较关键字 28 在区间(25,31),找到磁盘块 3 的指针 P2。
5、根据 P2 指针找到磁盘块 8,读入内存。【磁盘 I/O 操作第 3 次】
6、在磁盘块 8 中的关键字列表中找到关键字 28。
缺点:
1、每个节点都有key,同时 也包含data,而每个页存储空间是有限的,如果data比较大的话会导致每个节点存储的key数量变小
2、当存储的数据量很大的时候会导致深度较大,增大查询时磁盘io次数,进而影响查询性能
B+树:
B+Tree是在BTree的基础之上做的一种优化,变化如下:
1、B+Tree每个节点可以包含更多的节点,这个做的原因有两个,第一个原因是为了降低树的高度,第二个原因是将数据范围变为多个区间,区间越多,数据检索越快(非叶子结点不存储数据)
2、非叶子节点存储key,叶子节点存储key和数据
3、叶子节点两两指针相互连接(符合磁盘的预读特性),顺序查询性能更高
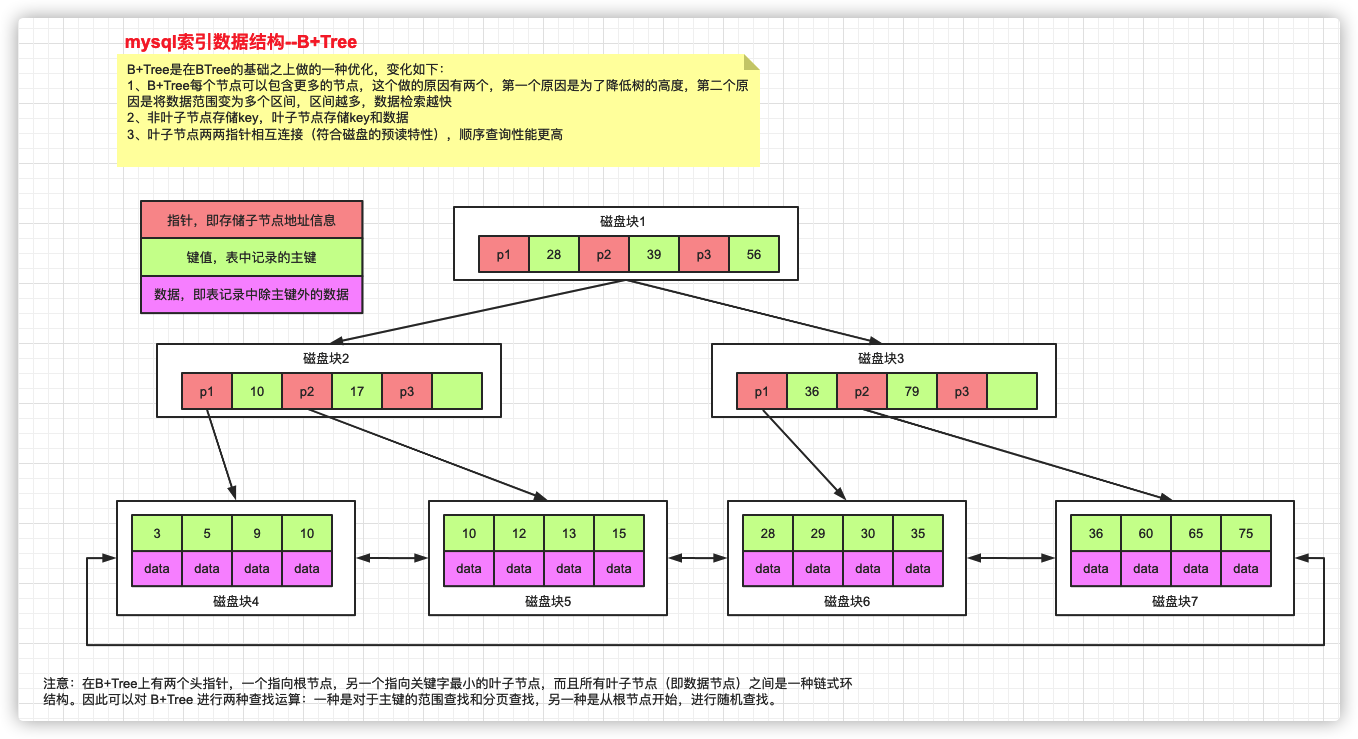
注意:
在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对 B+Tree 进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
InnoDB的B+树,叶子结点直接放置数据
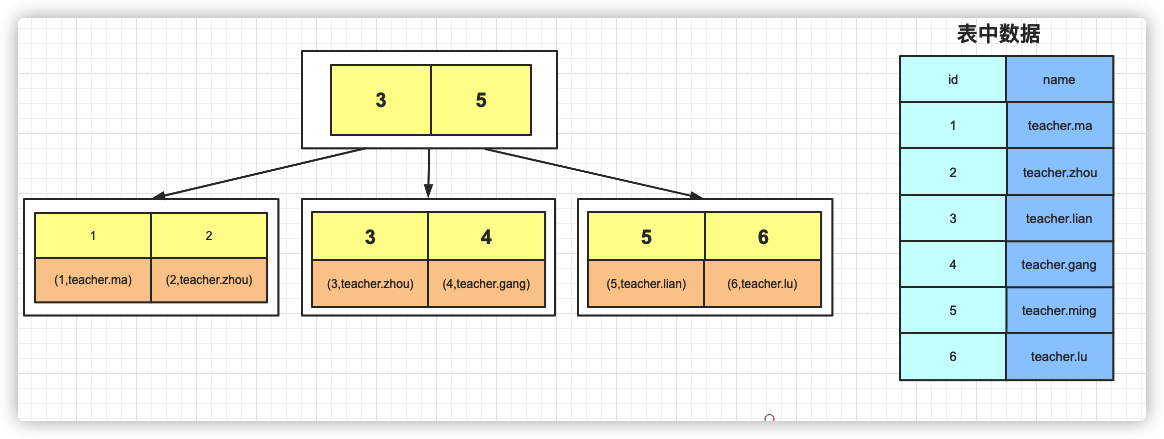
注意:
1、InnoDB是通过B+Tree结构对主键创建索引,然后叶子节点中存储记录,如果没有主键,那么会选择唯一键,如果没有唯一键,那么会生成一个6位的row_id来作为主键
2、如果创建索引的键是其他字段,那么在叶子节点中存储的是该记录的主键,然后再通过主键索引找到对应的记录,叫做
回表
如果给name创建索引,就会成为这样

通过找到对应数据的主键值,然后找到对应记录的数据,走了两次B+数
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !