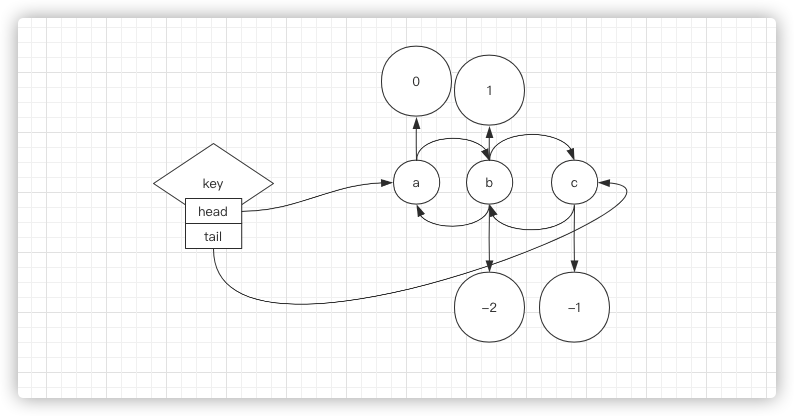
BLPOP key [key ...] timeout summary: Remove and get the first element in a list, or block until one is available since: 2.0.0
BRPOP key [key ...] timeout summary: Remove and get the last element in a list, or block until one is available since: 2.0.0
BRPOPLPUSH source destination timeout summary: Pop an element from a list, push it to another list and return it; or block until one is available since: 2.2.0
LINDEX key index summary: Get an element from a list by its index since: 1.0.0
LINSERT key BEFORE|AFTER pivot element summary: Insert an element before or after another element in a list since: 2.2.0
LLEN key summary: Get the length of a list since: 1.0.0
LPOP key summary: Remove and get the first element in a list since: 1.0.0
LPUSH key element [element ...] summary: Prepend one or multiple elements to a list since: 1.0.0
LPUSHX key element [element ...] summary: Prepend an element to a list, only if the list exists since: 2.2.0
LRANGE key start stop summary: Get a range of elements from a list since: 1.0.0
LREM key count element summary: Remove elements from a list since: 1.0.0
LSET key index element summary: Set the value of an element in a list by its index since: 1.0.0
LTRIM key start stop summary: Trim a list to the specified range since: 1.0.0 RPOP key summary: Remove and get the last element in a list since: 1.0.0
RPOPLPUSH source destination summary: Remove the last element in a list, prepend it to another list and return it since: 1.2.0
RPUSH key element [element ...] summary: Append one or multiple elements to a list since: 1.0.0
RPUSHX key element [element ...] summary: Append an element to a list, only if the list exists since: 2.2.0
127.0.0.1:6380>
1、lpush、rpush、lpop、LRANGE等
lpush从左边开往里面添加元素
1 2 3
127.0.0.1:6380> lpush k1 a b c d e f 6 # 存储顺序:f e d c b a
rpush从右边追加元素
1 2 3
127.0.0.1:6380> rpush k2 a b c d e f 6 # 存储顺序:a b c d e f
lpop,从左边弹出一个元素
1 2 3 4 5
127.0.0.1:6380> lpop k1 f 127.0.0.1:6380> lpop k1 e 127.0.0.1:6380>
同向的命令描述的是Java中的栈
1 2 3 4 5
127.0.0.1:6380> rpop k2 f 127.0.0.1:6380> rpop k2 e 127.0.0.1:6380>
list还能描述队列:反向命令描述的是Java中的队列,先进先出
LRANGE获取所有的元素
1 2 3 4 5 6 7 8 9 10 11
127.0.0.1:6380> LRANGE k1 0 -1 d c b a 127.0.0.1:6380> LRANGE k2 0 -1 a b c d 127.0.0.1:6380>
lindex 根据索引去除元素
1 2 3 4 5
127.0.0.1:6380> lindex k1 2 b 127.0.0.1:6380> lindex k1 -1 a 127.0.0.1:6380>
lset 根据索引给某个索引位置的元素赋值
1 2 3 4 5 6 7 8 9
127.0.0.1:6380> lset k1 2 aaaa OK 127.0.0.1:6380> LRANGE k1 0 -1 d c aaaa a 127.0.0.1:6380>
127.0.0.1:6380> lpush k31 a 2 b 3 a 4 c 5 a 6 d 12 127.0.0.1:6380> LRANGE k30 -1 d 6 a 5 c 4 a 3 b 2 a 1 127.0.0.1:6380> LREM k32 a # 移除两个a 2 127.0.0.1:6380> LRANGE k30 -1 d 6 5 c 4 3 b 2 a 1 127.0.0.1:6380>
我们先把刚remove的插回去linsert
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
127.0.0.1:6380> linsert k3 after 6 a # 在6的后面插入一个a ,如果有两个6 ,就会在第一个后面追加 11 127.0.0.1:6380> linsert k3 before 3 a # 在3的前面插入一个a 12 127.0.0.1:6380> LRANGE k3 0 -1 d 6 a 5 c 4 a 3 b 2 a 1 127.0.0.1:6380>
继续使用lrem从后面开始移除两个a
1 2 3 4 5 6 7 8 9 10 11 12 13 14
127.0.0.1:6380> lrem k3 -2 a 2 127.0.0.1:6380> LRANGE k3 0 -1 d 6 a 5 c 4 3 b 2 1 127.0.0.1:6380>
127.0.0.1:6380> hset steven name 石福鹏 # hset 1 127.0.0.1:6380> hset steven age 18 1 127.0.0.1:6380> hset steven address china 1 127.0.0.1:6380> hget steven name # hget 石福鹏 127.0.0.1:6380> hget steven age 18 127.0.0.1:6380> HMGET steven name age address # HMGET 石福鹏 18 china 127.0.0.1:6380> hkeys steven # hkeys name age address 127.0.0.1:6380> HVALS steven # HVALS 石福鹏 18 china 127.0.0.1:6380> HGETALL steven # HGETALL name 石福鹏 age 18 address china 127.0.0.1:6380>
也支持数值计算
1 2 3 4 5 6 7 8
127.0.0.1:6380> HINCRBYFLOAT steven age 0.5 # HINCRBYFLOAT 18.5 127.0.0.1:6380> hget steven age 18.5 127.0.0.1:6380> HINCRBYFLOAT steven age -1 # 没有减,但是加法也可以做减法 17.5 127.0.0.1:6380>
127.0.0.1:6380> help zadd key 存在再设置 ZADD key [NX|XX] [CH] [INCR] score member [score member ...] summary: Add one or more members to a sorted set, or update its score if it already exists since: 1.2.0 group: sorted_set
存储后的结果,物理内存中是左小右大
1 2 3 4 5 6 7
127.0.0.1:6380> ZADD k2 8 apple 2 banana 3 orange 3 127.0.0.1:6380> ZRANGE k2 0 -1 banana orange apple 127.0.0.1:6380>
也可以在结果中带分值ZRANGE k2 0 -1 withscores
ZRANGEBYSCORE按照分值取
1 2 3 4
127.0.0.1:6380> ZRANGEBYSCORE k2 3 8 orange apple 127.0.0.1:6380>
ZREVRANGE从高到低取出分值前两个
1 2 3 4
127.0.0.1:6380> ZREVRANGE k2 0 1 apple orange 127.0.0.1:6380>
127.0.0.1:6380> ZADD k380 tom 60 sean 70 steven 3 127.0.0.1:6380> ZADD k460 tom 100 sean 40 yiming 3 127.0.0.1:6380> ZUNIONSTORE unkey 2 k3 k4 4 127.0.0.1:6380> ZRANGE unkey 0 -1 withscores yiming 40 steven 70 tom 140 sean 160 127.0.0.1:6380>
加入权重,先分值乘以权重,然后再进行sum
1 2 3 4 5 6 7 8 9 10 11 12
127.0.0.1:6380> ZUNIONSTORE unkey 2 k3 k4 weights 1 0.5 # 加入权重 1就是k1的分值乘以1,0.5就k2分值乘以0.5 4 127.0.0.1:6380> ZRANGE unkey 0 -1 withscores yiming 20 steven 70 sean 110 tom 110 127.0.0.1:6380>
加入分值规则
1 2 3 4 5 6 7 8 9 10 11 12
127.0.0.1:6380> ZUNIONSTORE unkey 2 k3 k4 aggregate max 4 127.0.0.1:6380> ZRANGE unkey 0 -1 withscores yiming 40 steven 70 tom 80 sean 100 127.0.0.1:6380>
在权重的基础上,加入分值规则
1 2 3 4 5 6 7 8 9 10 11 12
127.0.0.1:6380> ZUNIONSTORE unkey 2 k3 k4 weights 1 0.5 aggregate max 4 127.0.0.1:6380> ZRANGE unkey 0 -1 withscores yiming 20 sean 60 steven 70 tom 80 127.0.0.1:6380>