由于本人最开始是从事.NET,PHP开发的,由于工作和自己的一些技术需要,开始准备将Java作为主要的开发语言,一开始都是直接开始上手公司的项目,因此利用空暇时间系统的学习Java知识体系,记录自己容易忽视的问题
Java的两种核心机制
- Java虚拟机
- 垃圾回收机制
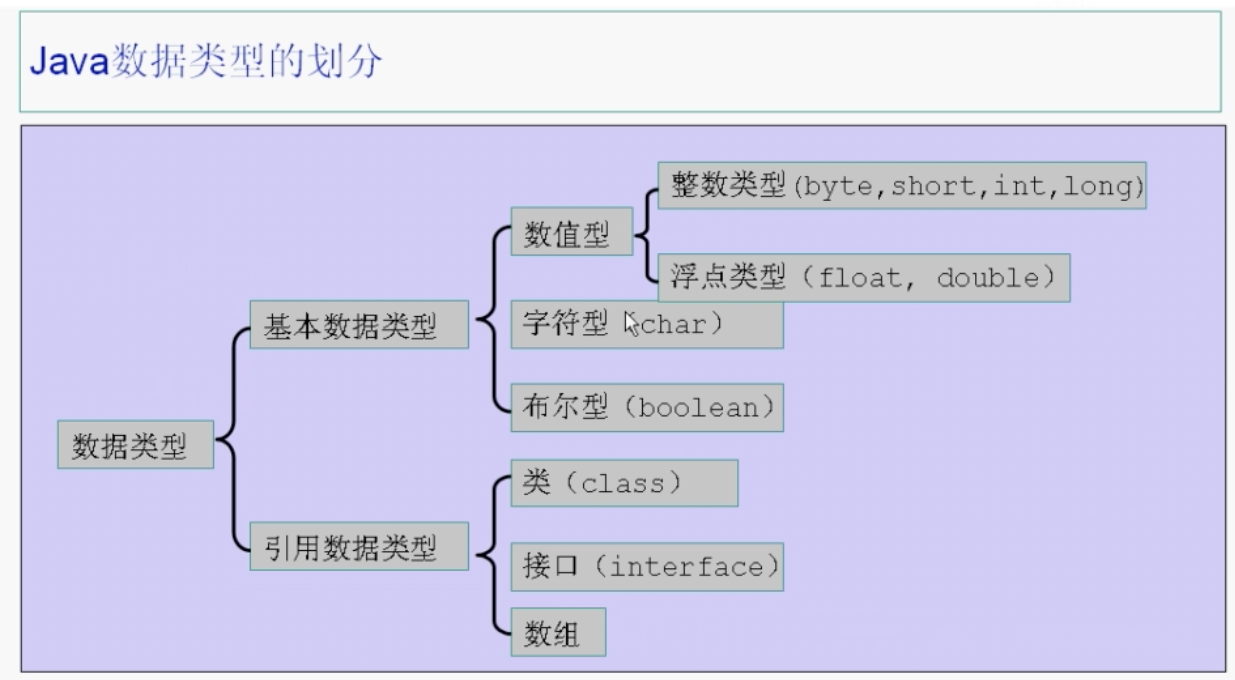
知识点1: Java数据类型的划分
知识点2:容量小的类型自动转化为容量大的数据类型
byte,short,char之间不会相互转化,他们三只直接在运算时首先会转化为int类型
1 | byte b1 = 1; |
知识点3:如何在内存中区分类和堆
-
类是静态的概念,是放在代码区里面的
-
对象是new出来的,位于堆内存(动态分配内存的),类的每个成员变量在不同的对象中都有不同的值(除了静态变量),而方法只有一份,执行的时候才占内存
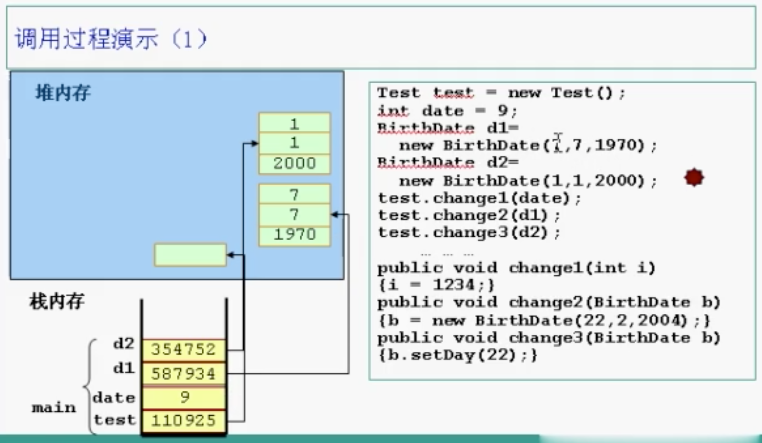
知识点4:对象内存分配
1 | public class Test{ |
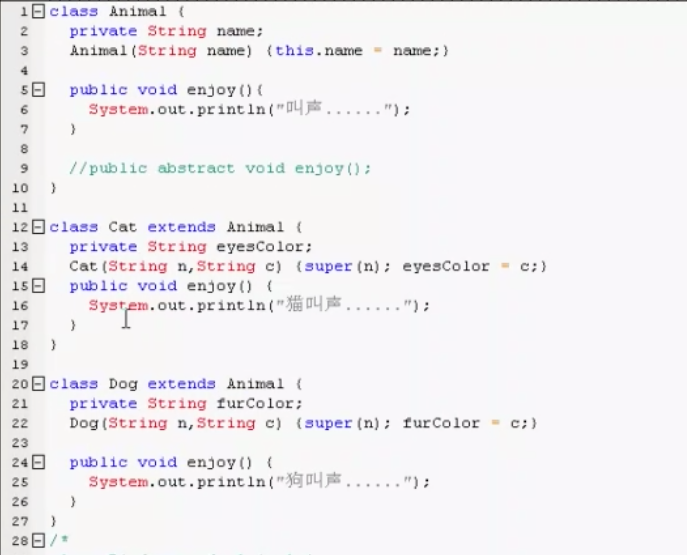
知识点5: super:在Java类中使用super来引用基类的成分
this是当前对象的引用,super是当前对象的父类对象的引用
知识点6:子类和父类
-
子类的构造的过程中必须调用其基类的构造方法
-
子类可以在自己的构造方法中使用super(args) 调用基类的构造方法
- 使用this(args)调用自己的类的其他的构造方法
- 如果调用了super,必须写在子类构造方法的第一行
-
如果子类的构造方法中没有显示的调用基类构造方法,系统默认调用基类无参数的构造方法,
-
如果子类构造方法中既没有显式调用基类构造方法,而基类中又没有无参的构造方法,则编译会出错
1 | public class SuperTest { |
知识点7:Object类
Object类是所有的Java类的根基类,如果在类的声明中未使用extends关键字制定其基类,则默认基类为Object类
知识点8: 对象转型(casting)
-
一个基类的引用类型变量可以“指向”其子类的对象(即需要的是动物对象,你可以传递一只狗进来)
-
一个基类的引用不可以访问其子类对象增加的成员(属性和方法)(需要的动物,传入一只狗的对象进来,那么这里是把这只狗当作一只动物传进来的,狗新增加的成员就不能使用)
-
可以使用 引用 变量 instanceof 类名 来判断该引用型变量所指向的对象是否属于该类或者该类的子类(即一个对象是否为一个类的实例)
注意:编译器会检查 obj 是否能转换成右边的class类型,如果不能转换则直接报错,如果不能确定类型,则通过编译,具体看运行时定。

- 子类对象可以当作基类对象来使用称作为向上转型,反之称为向下转型
知识点9: 动态绑定和多态
new的什么对象,调用的时候就会调用该对象的方法
多态是同一个行为具有多个不同表现形式或形态的能力。
多态就是同一个接口,使用不同的实例而执行不同操作。
多态存在的三个必要条件
- 继承
- 重写
- 父类引用指向子类对象
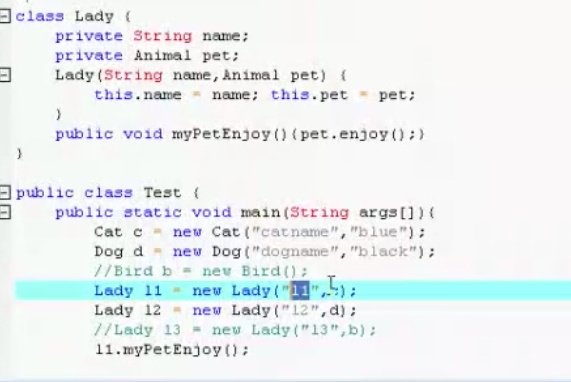
知识点10: Final关键字
- final的变量不能被改变
- final的方法不能够被重写
- final的类不能够被继承
知识点11: 接口特性
-
接口中声明的属性默认为public static final的,也只能是public static final的(默认是省略的);
-
接口中只能定义抽象方法,而且这些方法默认为public的,也只能是public的
知识点12: Java中的异常
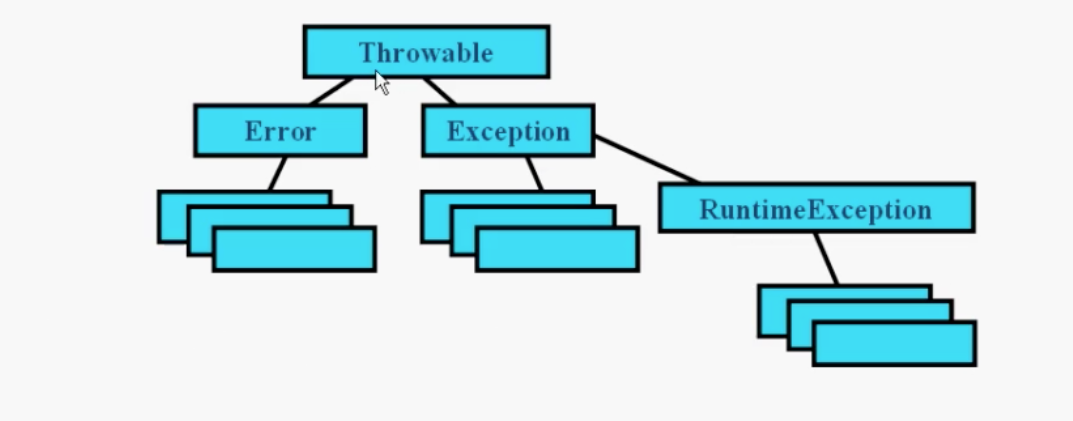
Throwable:根异常:可被抛出的
Error:系统的错误,虚拟机出错了,我们处理不了的错误
Exception:我们可以catch的错误
知识点13:创建数组内存变化

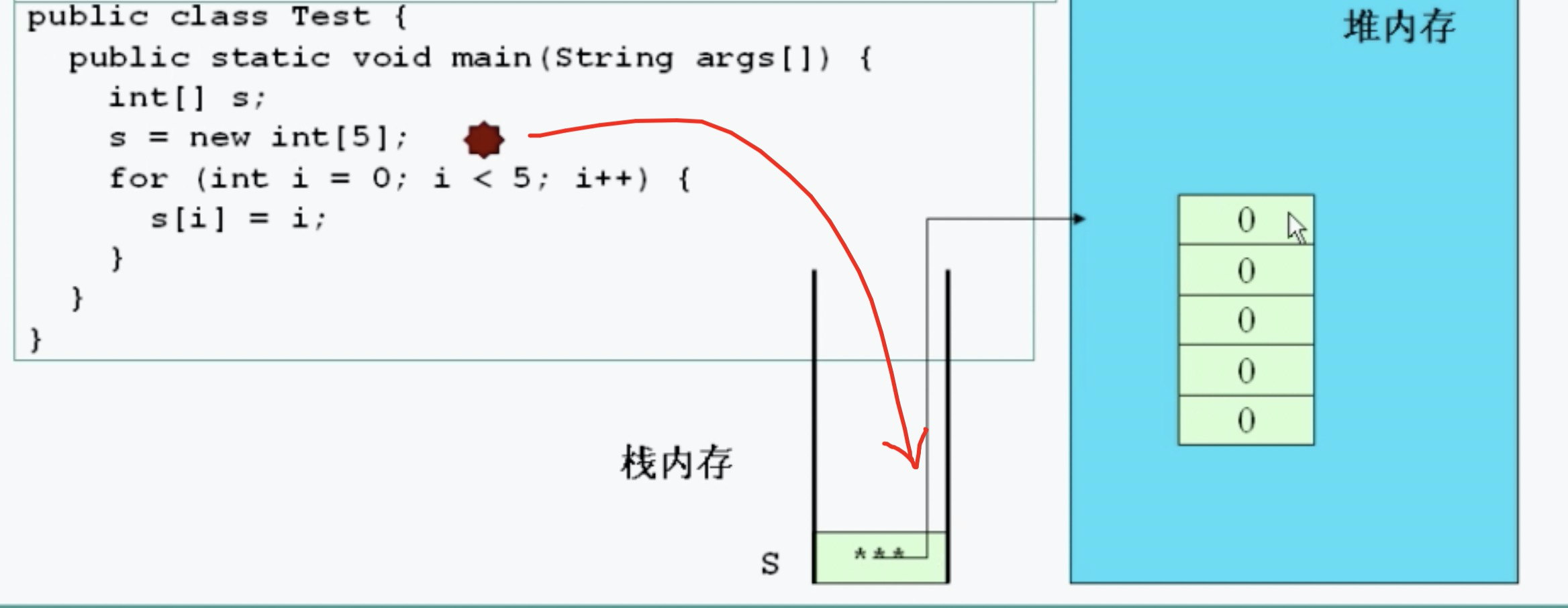
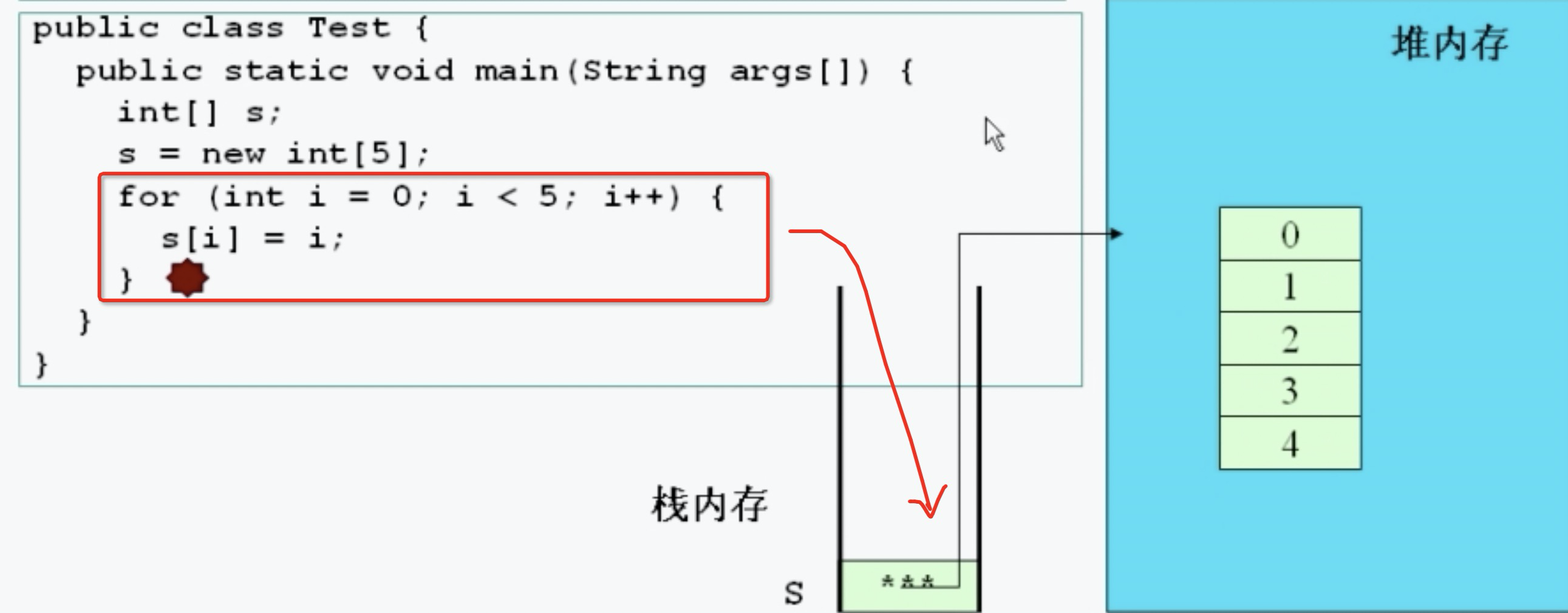
元素为引用数据类型 数组中每一个元素都需要实例化
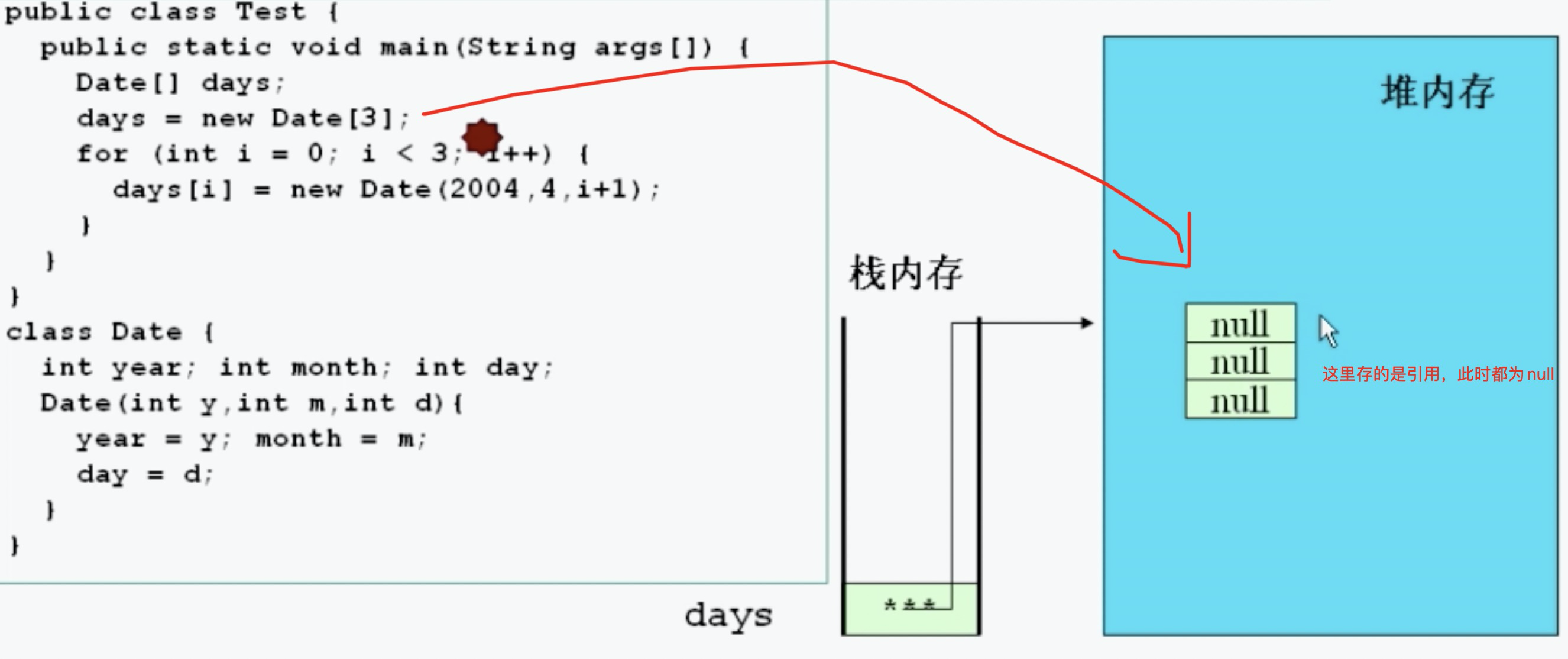
知识点14:数组元素的默认初始化
数组是引用类型,他的元素相当于类的成员变量,因此数组分配空间后,每个元素也被按照成员变量的规则被隐氏初始化
知识点15:500个人,手拉手围成一圈。数三退一,最后剩下的人原来排在什么位置?
1 | public static void main(String[] args) { |
也可以用面向对象的方式实现
知识点16: 数组拷贝System.arraycopy()
一般的数据拷贝的方式有:
- for遍历:遍历源数组并将每个元素赋给目标数组。
- clone:原数组调用clone方法克隆新对象赋给目标数组
- System.arraycopy:JVM 提供的数组拷贝实现。
- Arrays.copyof:实际也是调用System.arraycopy
参考:https://juejin.im/post/6844903573545811981
知识点17: String类
1 | String s1="hello"; |
知识点18:String类的常用方法
 g
g

知识点19:String类的静态重载方法
String.valueof():将基本类型数据转化为字符串
知识点20:判断一个字符是大写还是小写
当一个char做运算的时候,或者说比较大小的时候,实际上是比较他们的ascii编码
1 | String s = "AsaAAdFFASASSA*DSAAFDASA11554*saakda"; |
1 | //方法2: |
知识点21:StringBuffer
Buffer: 顾名思义,即缓冲区,通俗的来讲就是,内存里面有一小块区域,放什么东西先往这一小块区域放,然后再往其他地方放
java.lang.StringBuffer 代表可变的字符序列
什么叫可变、不可变?
1 | String a = "hello"; |
而使用StringBuffer的话,就是直接在屁股后面开辟内存,不用再copy了
结论:StringBuffer和String类似,但是StringBuffer可以对其字符串进行改变
举例:使用String对一个字符串进行操作,即删除字符串中间的某个字符,String就需要讲要删除的字符前后都先截取出来,再作处理,但是StringBuffer就可以直接删除
知识点22:基本数据类型包装类
每一个基础的数据类型一般情况下都是分配到栈上,如果想把它封装成一个对象分配到堆上的话,使用基础数据类型的包装类
Integer、Float、Long、Boolean、Byte、Short、Double、Character
装箱: 基本类型转变为包装器类型(引用类型)的过程。
拆箱: 包装器类型转变为基本类型(引用类型)的过程。
装箱是通过调用包装器类的 valueOf() 方法实现的
拆箱是通过调用包装器类的 xxxValue() 方法实现的,xxx代表对应的基本数据类型。
知识点23:File 类
Java.io.File类代笔爱系统文件名(路径和文件名)
常见的构造方法:
1 | //以pathname为路径创建File对象,如果pathname是相对路径,则默认的当前路径在系统属性user.dir中存储 |
1 | //以parent为父路径,child为子路径,创建File对象 |
File的静态属性String separator 存储了当前系统的路径分隔符
比如,window下是反斜杠\,linux下是斜杠/


例子 :递归查询文件及其子文件
1 | private static void tree(File file, int level) { |
知识点24: 容器
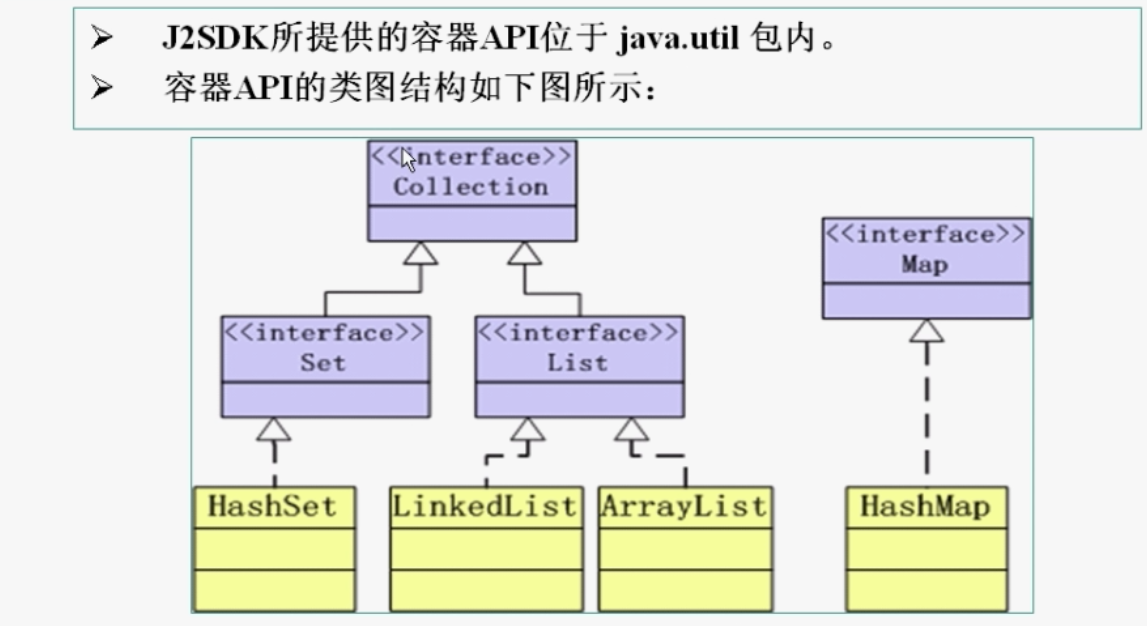
List、Set继承于Collection接口
List:有序(元素存入集合的顺序和取出的顺序一致),元素都有索引。元素可以重复。可以自动扩容
Set:无序(存入和取出顺序有可能不一致),不可以存储重复元素。必须保证元素唯一性。
1 | //Collection接口中定义的方法 |
1 | Collection c = new ArrayList(); |
注意: 容器类的对象在调用remove、contains等方法时需要比较对象是否相等,这会涉及到对象类型的equals方法和hashCode方法实现自定义的对象相等规则。
另外,相等的对象应该具有相等的hash codes
Java8中中的运用–Stream.distinct() 列表去重
distinct返回该流的不同元素组成的流,distinct是Stream接口的方法,distinct()使用hashcode()、equals()方法来获取不同的元素。因此,我们的类必须实现hashcode()、equals()。如果distinct()正在处理有序流,那么对于重复元素,将保留以遭遇顺序首先出现的元素,并且以这种方式选择不同元素是稳定的。
在无序流的情况下,不同元素的选择不一定是稳定的,是可以改变的。
distinct()执行有状态的中间操作。在有序流的并行流的情况下,保持distinct()的稳定性是需要很高的代价的,因为它需要大量的缓冲开销。如果我们不需要保持遭遇顺序的一致性,那么我们应该可以使用通过BaseStream.unordered()方法实现的无序流。
Stream.distinct()
distinct()方法的声明如下:
1 | Stream<T> distinct() |
它是Stream接口的方法。在此示例中,我们有一个包含重复元素的字符串数据类型列表
1 | package com.concretepage; |
-
List<Object>使用Stream.distinct()去重
为了对列表进行去重,该类将重写hashCode()和equals()1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class Book {
private String name;
private int price;
public Book(String name, int price) {
this.name = name;
this.price = price;
}
public String getName() {
return name;
}
public int getPrice() {
return price;
}
public boolean equals(final Object obj) {
if (obj == null) {
return false;
}
final Book book = (Book) obj;
if (this == book) {
return true;
} else {
return (this.name.equals(book.name) && this.price == book.price);
}
}
public int hashCode() {
int hashno = 7;
hashno = 13 * hashno + (name == null ? 0 : name.hashCode());
return hashno;
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public class DistinctWithUserObjects {
public static void main(String[] args) {
List<Book> list = new ArrayList<>();
{
list.add(new Book("Core Java", 200));
list.add(new Book("Core Java", 200));
list.add(new Book("Learning Freemarker", 150));
list.add(new Book("Spring MVC", 300));
list.add(new Book("Spring MVC", 300));
}
long l = list.stream().distinct().count();
System.out.println("No. of distinct books:"+l);
list.stream().distinct().forEach(b -> System.out.println(b.getName()+ "," + b.getPrice()));
}
}
//
//No. of distinct books:3
//Core Java,200
//Learning Freemarker,150
//Spring MVC,300 -
按照属性对对象列表进行去重
distinct()不提供按照属性对对象列表进行去重的直接实现。它是基于hashCode()和equals()工作的。如果我们想要按照对象的属性,对对象列表进行去重,我们可以通过其它方法来实现。如下代码段所示:
1 | static <T> Predicate<T> distinctByKey(Function<? super T, ?> keyExtractor) { |
上面的方法可以被Stream接口的 filter()接收为参数,如下所示:
1 | list.stream().filter(distinctByKey(b -> b.getName())); |
distinctByKey()方法返回一个使用ConcurrentHashMap 来维护先前所见状态的 Predicate 实例,如下是一个完整的使用对象属性来进行去重的示例。
1 | public class DistinctByProperty { |
知识点25:Iterator接口
所有实现了Collection接口的容器类都有一个iterator方法用于返回一个实现了iterator接口的对象
iterator对象称为迭代器,用于实现对容器内的元素进行遍历操作
1 | boolean hasnext(); //判断游标右边是否有元素 |
iterator对象的remove方法是在迭代过程中,删除元素的唯一的安全方法
知识点26:List常用算法
void sort(List)对list容器中的元素排序
void shuffle(List)对list容器内的对象进行随机排列
void reverse对容器中的对象进行逆序排列
void fill(List,Object)用一个特定的对象重写整个List容器
void copy(List dest,List srv)讲src List容器内容拷贝到dest List中
int binarySearch(List,Object) 对于顺序的List容器,采用折半查找的方法查找特定对象
上述算法根据什么确定容器中对对象的大小的?
所有可以排序的类都实现了java.lang,Comparable接口,并且该接口中只有一个方法public int compareTo(object obj)
==0:表示相等
>0:this>obj
<0:this<obj
知识点27:如何选择数据结构
衡量标准:读的效率和改的效率
array:读快改慢
Linked:改快写慢
具体参考这篇文章数组查询为什么比链表快
如果您喜欢此博客或发现它对您有用,则欢迎对此发表评论。 也欢迎您共享此博客,以便更多人可以参与。 如果博客中使用的图像侵犯了您的版权,请与作者联系以将其删除。 谢谢 !